رگرسیون خطی (Linear Regression) با پایتون — راهنمای کاربردی
«رگرسیون خطی» (Linear regression)، یکی از الگوریتمهای «یادگیری ماشین» (Machine Learning) «نظارت شده» (Supervised Learning) است. این الگوریتم، با مشاهده ویژگیهای پیوسته، خروجی را پیشبینی میکند. بسته به اینکه الگوریتم روی یک متغیر اجرا شود و یا روی ویژگیهای زیاد، به آن «رگرسیون خطی ساده» (simple linear regression) یا «رگرسیون خطی چندگانه» (multiple linear regression) گفته میشود.
رگرسیون خطی، یکی از الگوریتمهای یادگیری ماشین بسیار محبوب محسوب میشود که در مسائل گوناگون کاربرد دارد.این الگوریتم، وزنهای بهینه را به متغیرها تخصیص میدهد تا یک خط ax+b برای پیشبینی خروجیها بسازد. معمولا از رگرسیون خطی برای تخمین «مقادیر حقیقی» (Real Values) مانند تعداد درخواستها و نرخ قیمت خانهها بر اساس متغیرهای پیوسته استفاده میشود. خط رگرسیون، بهترین خطی است که Y=a*X+b را برازش میکند تا رابطهای را بین متغیر وابسته و مستقل نشان دهد. در ادامه، از این روش برای دادههای «مجموعه داده دیابت» (diabetes dataset) استفاده میشود.
قطعه کد ۱:
>>> import matplotlib.pyplot as plt
>>> import numpy as np
>>> from sklearn import datasets,linear_model
>>> from sklearn.metrics import mean_squared_error,r2_score
>>> diabetes=datasets.load_diabetes()
>>> diabetes_X=diabetes.data[:,np.newaxis,2]
>>> diabetes_X_train=diabetes_X[:-30] #splitting data into training and test sets
>>> diabetes_X_test=diabetes_X[-30:]
>>> diabetes_y_train=diabetes.target[:-30] #splitting targets into training and test sets
>>> diabetes_y_test=diabetes.target[-30:]
>>> regr=linear_model.LinearRegression() #Linear regression object
>>> regr.fit(diabetes_X_train,diabetes_y_train) #Use training sets to train the model
قطعه کد ۲:
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
قطعه کد ۳:
>>> diabetes_y_pred=regr.predict(diabetes_X_test) #Make predictions
>>> regr.coef_
array([941.43097333])
قطعه کد ۴:
>>> mean_squared_error(diabetes_y_test,diabetes_y_pred)
خروجی:
۳۰۳۵٫۰۶۰۱۱۵۲۹۱۲۶۹۵
>>> r2_score(diabetes_y_test,diabetes_y_pred) #Variance score
خروجی:
۰٫۴۱۰۹۲۰۷۲۸۱۳۵۸۳۵
قطعه کد ۵:
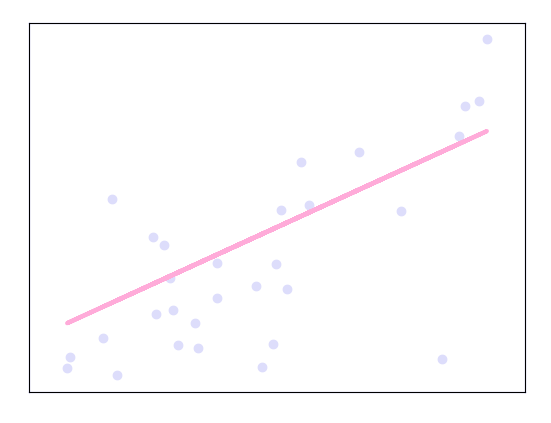
>>> plt.scatter(diabetes_X_test,diabetes_y_test,color =’lavender’)
<matplotlib.collections.PathCollection object at 0x0584FF70>
قطعه کد ۶:
>>> plt.plot(diabetes_X_test,diabetes_y_pred,color=’pink’,linewidth=3)
[<matplotlib.lines.Line2D object at 0x0584FF30>]
قطعه کد ۷:
>>> plt.xticks(())
([], <a list of 0 Text xticklabel objects>)
قطعه کد ۸:
>>> plt.yticks(())
([], <a list of 0 Text yticklabel objects>)
قطعه کد ۹:
>>> plt.show()
 اگر نوشته بالا برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
اگر نوشته بالا برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای آمار، احتمالات و دادهکاوی
- آموزش همبستگی و رگرسیون خطی در SPSS
- مجموعه آموزشهای نرمافزارهای آماری
- دادهکاوی (Data Mining) — از صفر تا صد
- یادگیری علم داده (Data Science) با پایتون — از صفر تا صد
- زبان برنامهنویسی پایتون (Python) — از صفر تا صد
مجموعه: آمار, داده کاوی, یادگیری ماشینی
