الگوریتم اپریوری در پایتون — به زبان ساده
«اپریوری» (Apriori)، الگوریتم محبوبی برای استخراج «مجموعه اقلام مکرر» (Frequent Itemsets) و با کاربردهای متعدد در یادگیری «قواعد وابستگی» (Association Rules) است. الگوریتم اپریوری برای عمل کردن روی «پایگاهدادههای» (Databases) حاوی تراکنش مانند خریدهای مشتریان از یک فروشگاه، مورد استفاده قرار میگیرد. یک «مجموعه اقلام» (itemset)، مکرر محسوب میشود اگر به آستانه «پشتیبان» تعیین شده توسط کاربر برسد. برای مثال، اگر آستانه پشتیبان روی ۰/۵ (٪۵۰) تنظیم شود، یک مجموعه اقلام مکرر به عنوان مجموعهای از اقلام محسوب میشود که دستکم در ٪۵۰ از همه تراکنشهای پایگاه داده وجود داشته باشد.
گام ۱: ساخت یک مجموعه اقلام مکرر
تابع اپریوری در پایتون، با دادههای کدگذاری شده به روش وانهات (One-Hot) در دیتافریمهای کتابخانه «پانداس» (Pandas) کار میکند. فرض میشود که دادههای تراکنشی زیر موجود هستند.
dataset = [[‘Milk’, ‘Onion’, ‘Nutmeg’, ‘Kidney Beans’, ‘Eggs’, ‘Yogurt’],
[‘Dill’, ‘Onion’, ‘Nutmeg’, ‘Kidney Beans’, ‘Eggs’, ‘Yogurt’],
[‘Milk’, ‘Apple’, ‘Kidney Beans’, ‘Eggs’],
[‘Milk’, ‘Unicorn’, ‘Corn’, ‘Kidney Beans’, ‘Yogurt’],
[‘Corn’, ‘Onion’, ‘Onion’, ‘Kidney Beans’, ‘Ice cream’, ‘Eggs’]]
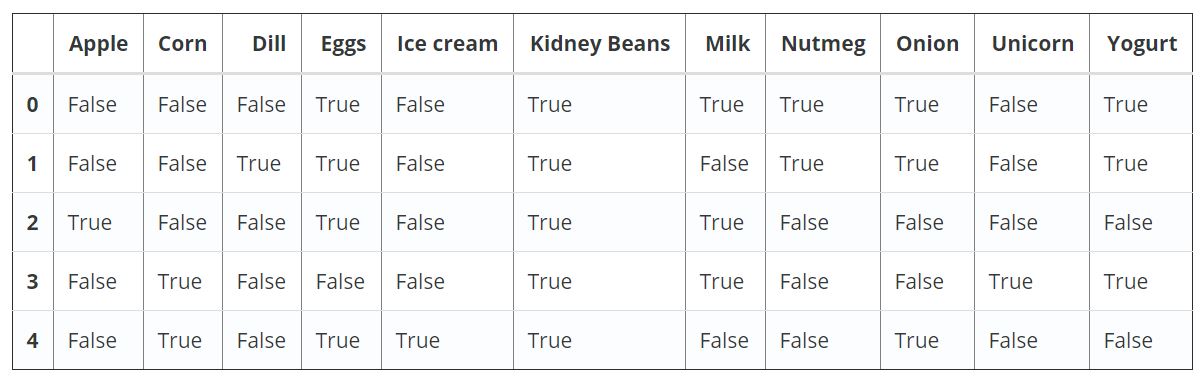
اکنون، باید این مجموعه داده را با استفاده از TransactionEncoder به فرمت مناسب تبدیل کرد. قطعه کد لازم برای انجام این کار در ادامه آمده است.
import pandas as pd
from mlxtend.preprocessing import TransactionEncoder
te = TransactionEncoder()
te_ary = te.fit(dataset).transform(dataset)
df = pd.DataFrame(te_ary, columns=te.columns_)
df
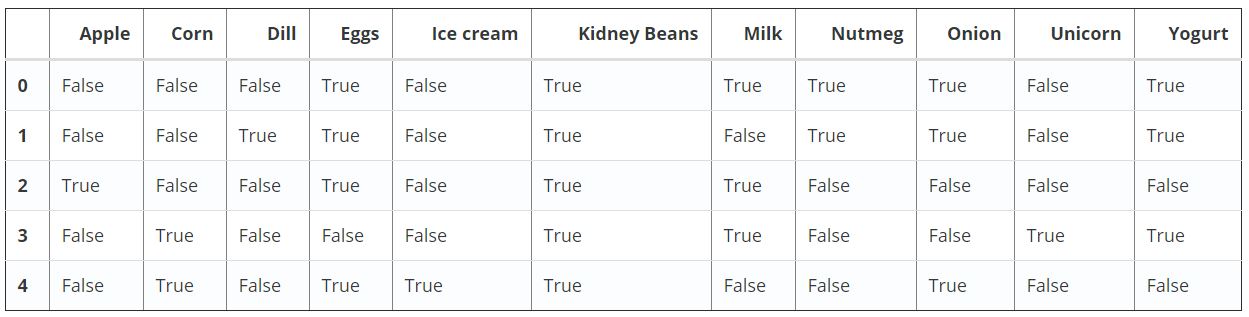
اکنون، اقلام و مجموعه اقلام با حداقل ٪۶۰ پشتیبان در خروجی بازگردانده (ارائه) میشوند.
from mlxtend.frequent_patterns import apriori
apriori(df, min_support=0.6)
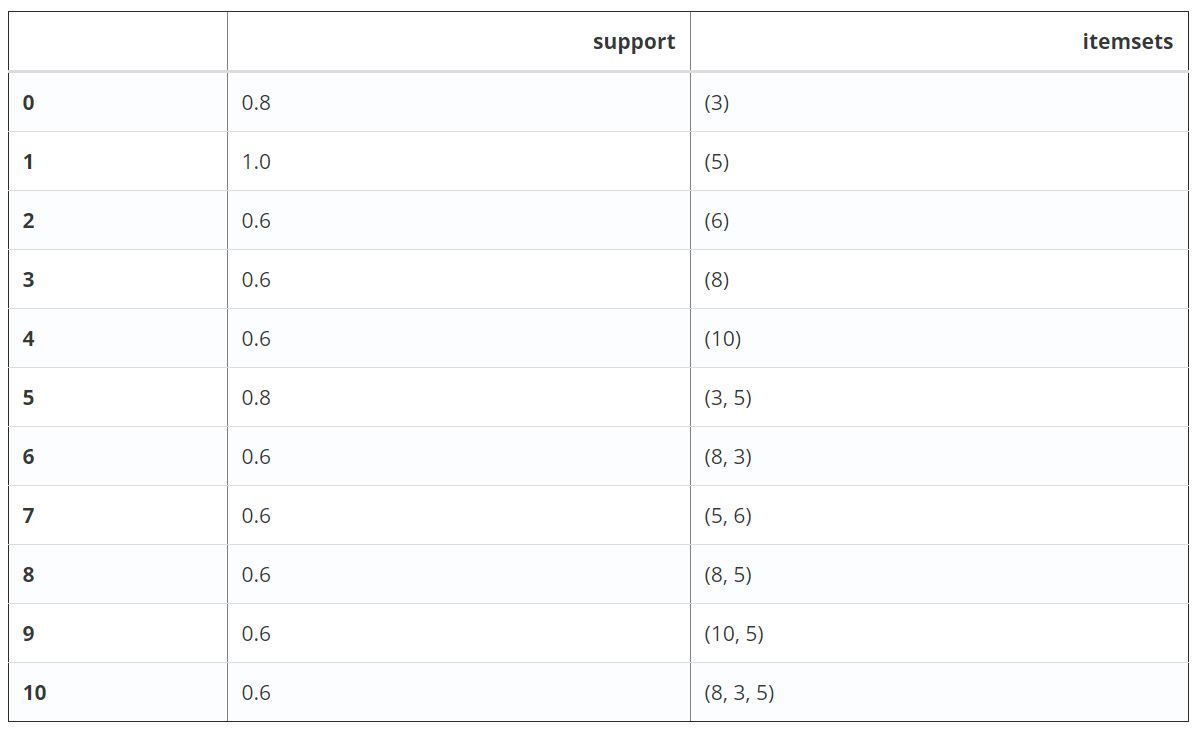
به طور پیشفرض، الگوریتم اپریوری (Apriori)، ستون شاخصهای اقلام را باز میگرداند، که میتواند در عملیات «پاییندستی» (Downstream Operations) مانند کاوش قواعد انجمنی مفید واقع شود. برای داشتن خوانایی بالاتر، میتوان use_colnames=True را تنظیم کرد تا این مقادیر «صحیح» (Integer) به اسامی اقلام مربوطه تبدیل شوند.
apriori(df, min_support=0.6, use_colnames=True)
گام ۲: انتخاب و پالایش نتایج
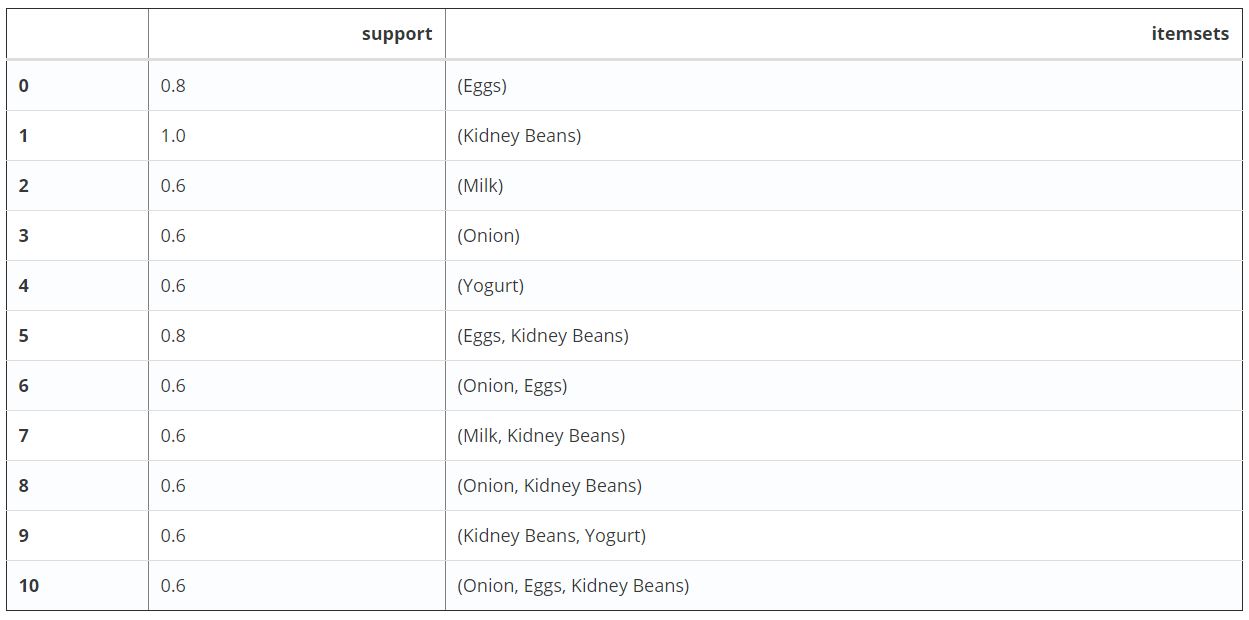
مزیت کار با «دیتافریم» (DataFrames) پانداس، آن است که میتوان از ویژگیهای مناسب آن برای فیلتر کردن نتایج استفاده کرد. برای مثال، میتوان فرض کرد که تمایل تنها به یافتن مجموعه اقلامی با طول دو (۲) است که دارای حداقل پشتیبان ٪۸۰ هستند. ابتدا، میتوان مجموعه اقلام مکرر را با apriori ساخت و سپس، یک ستون جدید اضافه کرد که طول هر مجموعه اقلام را نشان میدهد. کد مربوط به انجام این کار در پایتون، در ادامه آمده است.
frequent_itemsets = apriori(df, min_support=0.6, use_colnames=True)
frequent_itemsets[‘length’] = frequent_itemsets[‘itemsets’].apply(lambda x: len(x))
frequent_itemsets
سپس، میتوان نتایجی را انتخاب کرد که معیار مورد نظر را به صورتی که در کد زیر آمده، ارضا کنند.
frequent_itemsets[ (frequent_itemsets[‘length’] == 2) &
(frequent_itemsets[‘support’] >= 0.8) ]
| support | itemsets | length | |
|---|---|---|---|
| ۰٫۸ | (Eggs, Kidney Beans) | ۲ | ۵ |
به طور مشابه، با استفاده از API پانداس، میتوان ورودیها را بر مبنای ستون “itemsets” انتخاب کرد.
frequent_itemsets[ frequent_itemsets[‘itemsets’] == {‘Onion’, ‘Eggs’} ]
| support | itemsets | length | |
|---|---|---|---|
| ۰٫۶ | (Onion, Eggs) | ۲ | ۶ |
Frozensetها
توجه به این نکته لازم است که ورودیها در ستون «itemsets» از نوع frozenset هستند. frozenset یک نوع توکار در پایتون است که مشابه نوع set است، با این تفاوت که Frozensetها غیر قابل تغییر هستند. این موضوع، موجب کارآمدتر شدن frozensetها برای نوع خاصی از «کوئریها» (Query) یا عملیات مقایسه میشود. با توجه به اینکه frozensetها «مجموعه» هستند، ترتیب اقلام داخل آنها اهمیتی ندارد. برای مثال کوئری که در زیر آمده است،
frequent_itemsets[ frequent_itemsets[‘itemsets’] == {‘Onion’, ‘Eggs’} ]
با کوئری که در ادامه میآید یکی هستند.
- frequent_itemsets[ frequent_itemsets[‘itemsets’] == {‘Eggs’, ‘Onion’} ]
- frequent_itemsets[ frequent_itemsets[‘itemsets’] == frozenset((‘Eggs’, ‘Onion’)) ]
- frequent_itemsets[ frequent_itemsets[‘itemsets’] == frozenset((‘Onion’, ‘Eggs’)) ]
گام ۳: کار کردن با بازنمایی پراکنده
برای صرفهجویی در مصرف حافظه، ممکن است کاربر تمایل داشته باشد دادههای تراکنش را در قالب بازنمایی پراکنده داشته باشد (Sparse Representation). این کار به ویژه در صورتی که محصولات زیاد و تراکنشهای کوچکی وجود داشته باشد، مفید خواهد بود.
oht_ary = te.fit(dataset).transform(dataset, sparse=True)
sparse_df = pd.SparseDataFrame(te_ary, columns=te.columns_, default_fill_value=False)
sparse_df
apriori(sparse_df, min_support=0.6, use_colnames=True)

رابط برنامهنویسی کاربردی (API)
- apriori(df, min_support=0.5, use_colnames=False, max_len=None, n_jobs=1)
- دریافت مجموعه اقلام مکرر از پارامترهای دیتافریم (DataFrame) وانهات (one-hot)
- df: دیافریم پانداس (Pandas DataFrame) یا «دیتافریم پراکنده پانداس» (Pandas SparseDataFrame)
در ادامه، نسخه کدگذاری شده دیتافریم پانداس نمایش داده شده است. مقادیر پذیرفته شده ۰ و ۱ و یا در واقع درست/غلط (True/False) هستند.
- min_support: ممیز شناور (پیشفرض: ۰/۵)
یک مقدار ممیز شناور بین ۰ و ۱ برای حداقل پشتیبانی از مجموعه اقلام بازگردانده میشود. پشتیبان به عنوان fraction transactions_where_item(s)_occur / total_transactions محاسبه میشود.
- use_colnames: بولین (مقدار پیشفرض: غلط)
در صورتی که مقدار درست (true) باشد، از اسامی ستونهای دیتافریم به جای شاخصهای ستون، در دیتافریم بازگردانده شده استفاده میکند.
- max_len: صحیح (مقدار پیشفرض: None)
حداکثر طول مجموعه اقلام تولید شده را نشان میدهد. در صورتی که None (پیشفرض) باشد، همه طولهای مجموعه اقلام ممکن (بر اساس شرایط اپریوری)، ارزیابی میشوند.
مقادیر بازگردانده شده
دیتافریم پانداس با ستونهای [‘support’, ‘itemsets’] از همه مجموعه اقلامی که به صورت >= min_support و < نسبت به max_len (اگر max_len برابر با None نباشد) هستند، بازگردانده میشود. هر مجموعه اقلام در ستون ‘itemsets’ نوعی ‘itemsets’ است که از انواع داده توکار پایتون محسوب میشود که رفتاری مشابه مجموعهها دارند با این تفاوت که غیر قابل تغییر هستند.
اگر مطلب بالا برای شما مفید بوده، آموزشهای زیر نیز به شما پیشنهاد میشود:
- مجموعه آموزشهای دادهکاوی و یادگیری ماشین
- مجموعه آموزشهای دادهکاوی یا Data Mining در متلب
- مجموعه آموزشهای هوش مصنوعی
- زبان برنامهنویسی پایتون (Python) — از صفر تا صد
- یادگیری ماشین با پایتون — به زبان ساده
- آموزش یادگیری ماشین با مثالهای کاربردی — مجموعه مقالات جامع وبلاگ فرادرس
- چگونه یک دانشمند داده شوید؟ — راهنمای گامبهگام به همراه معرفی منابع
مجموعه: دستهبندی نشده
