پیش بینی قیمت خانه با یادگیری ماشین — راهنمای کاربردی
در این مطلب، با استفاده از یک مجموعه داده، قیمت خانهها مدلسازی و پیش بینی قیمت خانه ها با بهرهگیری از «یادگیری ماشین» (Machine Learning) انجام میشود. قیمت یک خانه به موقعیت جغرافیایی آن، متراژ، سال ساخت، سال بازسازی شدن، تعداد اتاق خوابها، تعداد پارکینگها و دیگر موارد بستگی دارد. بنابراین، این فاکتورها در الگوی تعیین قیمت یک خانه موثر هستند. برای مثال، هر چه موقعیت جغرافیایی یک خانه بهتر باشد، قیمت آن نیز بالاتر است. از سوی دیگر، همه خانههای موجود در یک منطقه خاص و با متراژ مشابه نیز قیمت یکسانی ندارند. البته، تنوع در قیمتها در چنین شرایطی ممکن است به نوعی نویز باشد. هدف از این مطلب، پیدا کردن مدلی است که بتواند قیمت را به درستی مدل و از نویز چشمپوشی کند. روش و مفهوم مشابهی برای پیشبینی قیمت اتاقهای هتل نیز مورد استفاده قرار میگیرد. بنابراین، در آغاز کار نیاز به پیادهسازی روشهای با قاعدهسازی (Regularization) برای «رگرسیون خطی» (Linear Regression) به منظور پیشبینی قیمت خانهها است.
مجموعه داده قیمت خانه
یک «مجموعه داده» خوب از قیمتهای خانهها از این مسیر [+] در دسترس است.
import warnings
def ignore_warn(*args, **kwargs):
pass
warnings.warn = ignore_warn
import numpy as np
import pandas as pd
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
from scipy.stats import norm, skew
from sklearn import preprocessing
from sklearn.metrics import r2_score
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn.linear_model import ElasticNetCV, ElasticNet
from xgboost import XGBRegressor, plot_importance
from sklearn.model_selection import RandomizedSearchCV
from sklearn.model_selection import StratifiedKFold
pd.set_option(‘display.float_format’, lambda x: ‘{:.3f}’.format(x))
df = pd.read_csv(‘house_train.csv’)
df.shape
![]()
(df.isnull().sum() / len(df)).sort_values(ascending=False)[:20]
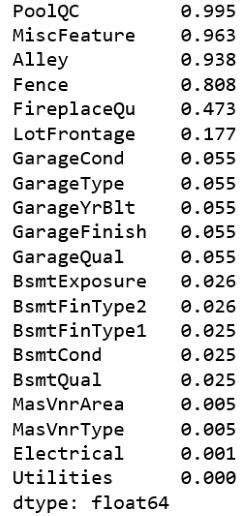
در این مجموعه داده، ویژگیهای متعددی وجود دارد (۸۱ ویژگی) و از این میان، ۱۹ ویژگی دارای مقادیر ناموجود هستند و ۴ ویژگی از این ویژگیها دارای بیش از ۸۰٪ مقادیر ناموجود هستند. با توجه به اینکه ۸۰٪ از مقادیر برای این جهار ویژگی ناموجود هستند، به نظر ویژگیهای مهمی نیستند (و حتی اگر مهم باشند، جایگزینی مقادیر برای آنها میتواند کاری مناقشه برانگیز باشد)، بنابراین این چهار ویژگی از مجموعه داده حذف میشوند. برای انجام این کار، از قطعه کد زیر استفاده شده است.
df.drop([‘PoolQC’, ‘MiscFeature’, ‘Alley’, ‘Fence’, ‘Id’], axis=1, inplace=True)
بررسی ویژگیها
در ادامه، اقداماتی در راستای بررسی ویژگیها انجام میشود. در گام اول، توزیع ویژگیهای هدف مورد بررسی قرار میگیرد.
sns.distplot(df[‘SalePrice’] , fit=norm);
# Get the fitted parameters used by the function
(mu, sigma) = norm.fit(df[‘SalePrice’])
print( ‘\n mu = {:.2f} and sigma = {:.2f}\n’.format(mu, sigma))
# Now plot the distribution
plt.legend([‘Normal dist. ($\mu=$ {:.2f} and $\sigma=$ {:.2f} )’.format(mu, sigma)],
loc=’best’)
plt.ylabel(‘Frequency’)
plt.title(‘Sale Price distribution’)
# Get also the QQ-plot
fig = plt.figure()
res = stats.probplot(df[‘SalePrice’], plot=plt)
plt.show();
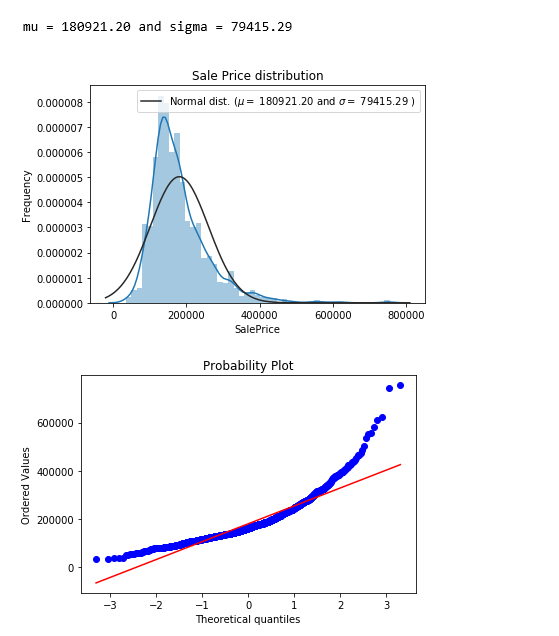
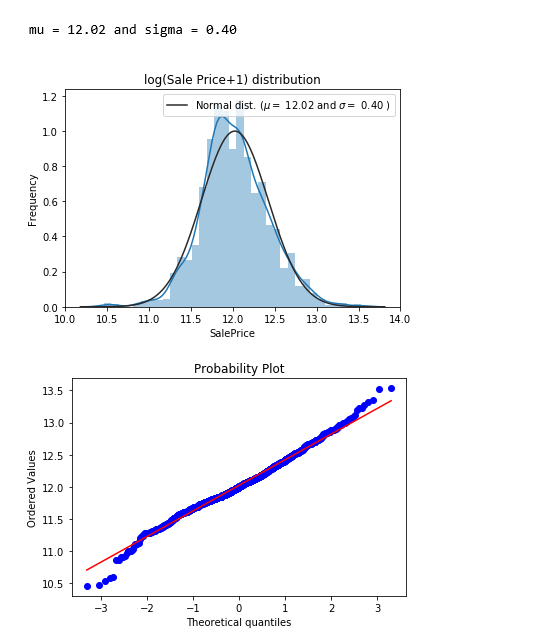
ویژگی هدف یعنی قیمت فروش (SalePrice) دارای چولگی به راست است. از آنجا که مدلهای خطی با دادههای دارای توزیع نرمال کار میکنند، در اینجا SalePrice تبدیل و توزیع آن نرمالتر میشود.
sns.distplot(np.log1p(df[‘SalePrice’]) , fit=norm);
# Get the fitted parameters used by the function
(mu, sigma) = norm.fit(np.log1p(df[‘SalePrice’]))
print( ‘\n mu = {:.2f} and sigma = {:.2f}\n’.format(mu, sigma))
# Now plot the distribution
plt.legend([‘Normal dist. ($\mu=$ {:.2f} and $\sigma=$ {:.2f} )’.format(mu, sigma)],
loc=’best’)
plt.ylabel(‘Frequency’)
plt.title(‘log(Sale Price+1) distribution’)
# Get also the QQ-plot
fig = plt.figure()
res = stats.probplot(np.log1p(df[‘SalePrice’]), plot=plt)
plt.show();
در ادامه، همبستگی بین ویژگیهای عددی مورد بررسی قرار میگیرد.
pd.set_option(‘precision’,2)
plt.figure(figsize=(10, 8))
sns.heatmap(df.drop([‘SalePrice’],axis=1).corr(), square=True)
plt.suptitle(“Pearson Correlation Heatmap”)
plt.show();
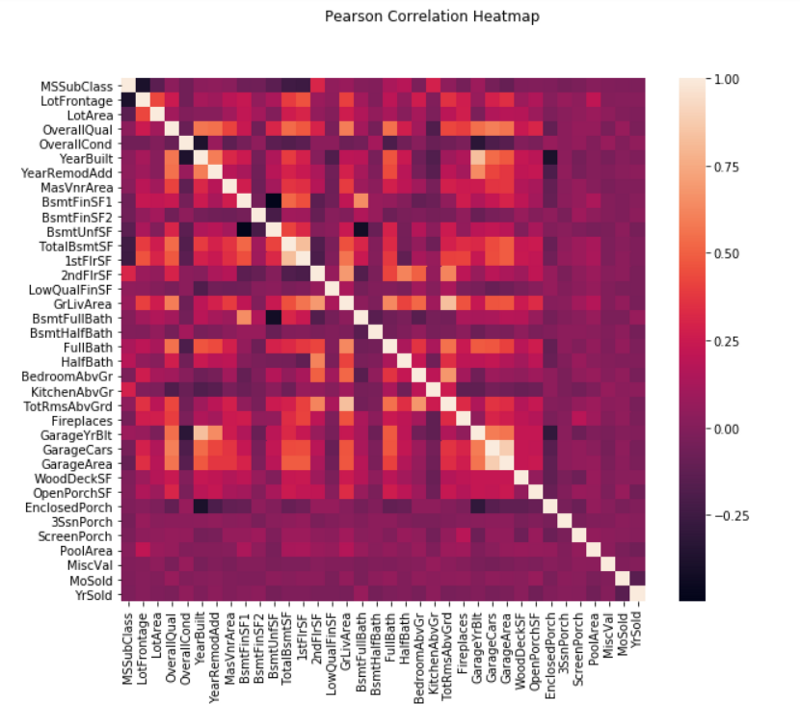
همانطور که از «نمودار حرارتی» (Heat Map) بالا مشهود است، همبستگی بسیار زیادی بین برخی از ویژگیها وجود دارد. برای مثال، GarageYrBlt و YearBuilt، همچنین TotRmsAbvGrd و GrLivArea و در نهایت GarageArea و GarageCars، به شدت به هم همبسته هستند. این ویژگیها در واقع تقریبا یک چیز واحد را بیان میکنند. بنابراین، در اینجا به منظور حذف افزونگی از روش با قاعدهسازی «الاستیکنت» (Elastic net) استفاده میشود. با استفاده از قطعه کد زیر، همبستگی بین SalePrice و دیگر ویژگیهای عددی محاسبه میشود.
corr_with_sale_price = df.corr()[“SalePrice”].sort_values(ascending=False)
plt.figure(figsize=(14,6))
corr_with_sale_price.drop(“SalePrice”).plot.bar()
plt.show();
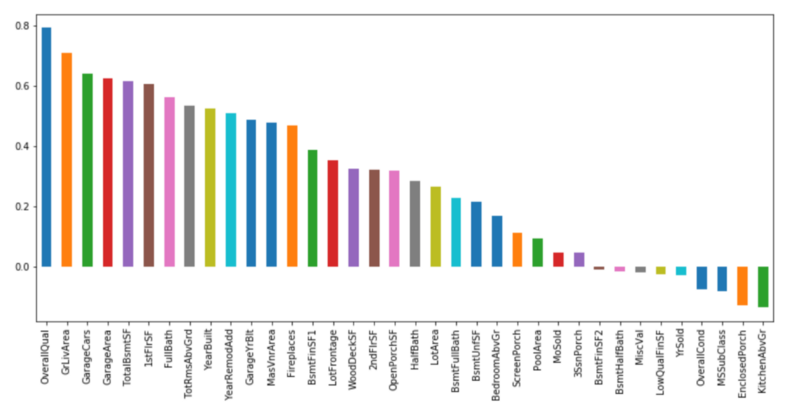
همبستگی SalePrice با OverallQual بیشتر از سایر موارد است (برابر با ۰.۸). همچنین، GrLivArea دارای همبستگی بیش از ۰.۷ و GarageCars دارای همبستگی بیش از ۰.۶ است. در ادامه، نگاهی همراه با جزئیات بیشتر به این ۴ ویژگی خواهد شد.
sns.pairplot(df[[‘SalePrice’, ‘OverallQual’, ‘GrLivArea’, ‘GarageCars’]])
plt.show();
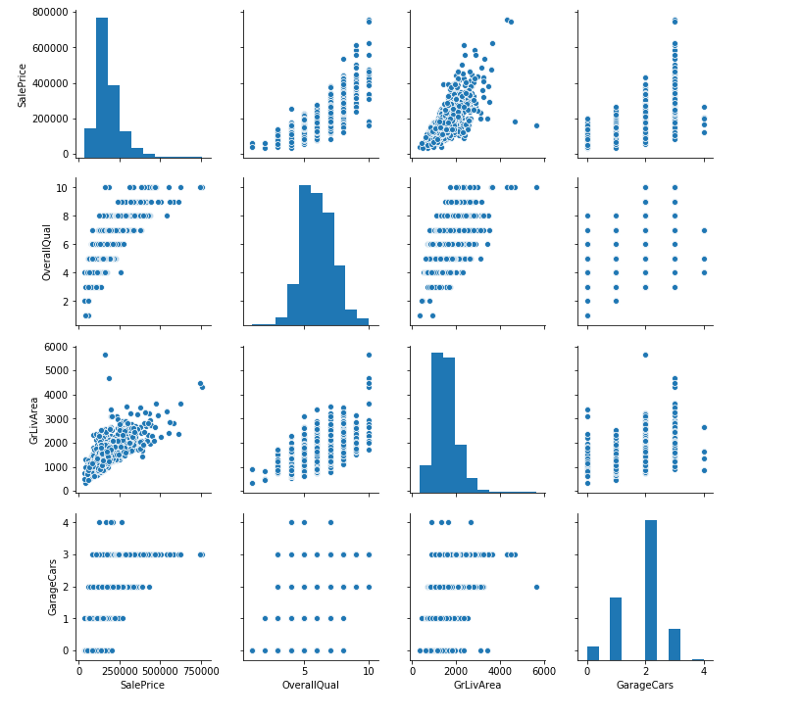
مهندسی ویژگیها
- لگاریتم (Log) ویژگیهایی را که دارای توزیع به شدت چوله هستند تبدیل میکند (چولگی > ۰.۷۵).
- تبدیل «ویژگیهای طبقهای» (Categorical Features) به «متغیرهای مجازی» (Dummy Variable) انجام میشود.
- جایگزینی مقادیر NaN با میانگین ستون انجام میشود.
- جداسازی مجموعههای آموزش و آزمون صورت میپذیرد.
df[“SalePrice”] = np.log1p(df[“SalePrice”])
#log transform skewed numeric features:
numeric_feats = df.dtypes[df.dtypes != “object”].index
skewed_feats = df[numeric_feats].apply(lambda x: skew(x.dropna())) #compute skewness
skewed_feats = skewed_feats[skewed_feats > 0.75]
skewed_feats = skewed_feats.index
df[skewed_feats] = np.log1p(df[skewed_feats])
df = pd.get_dummies(df)
df = df.fillna(df.mean())
X, y = df.drop([‘SalePrice’], axis = 1), df[‘SalePrice’]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
کد مربوط به مهندسی ویژگیها با نام feature_engineering_price.py ذخیره میشود.
الاستیکنت
- «رگرسیون لاسو» (Lasso Regression) و «رگرسیون ستیغی» (Ridge Regression) مدلهای رگرسیون خطی قاعدهمند شده هستند.
- ElasticNet اساسا یک ترکیب از رگرسیون لاسو و ستیغی است که مستلزم کمینهسازی تابع هدفی است که شامل نُرمهای L1 (لاسو) و L2 (ستیغی) میشود.
- الاستیکنت، هنگامی مفید است که چندین ویژگی همبسته با یکدیگر وجود دارد.
- کلاس ElasticNetCV برای تنظیم پارامترهای آلفا (نماد α) و l1_ratio (نماد ρ) با اعتبارسنجی متقابل قابل استفاده است.
- ElasticNetCV: مدل ElasticNet با بهترین انتخاب مدل به وسیله اعتبارسنجی متقابل است.
در ادامه، کد ElasticNetCV در پایتون پیادهسازی شده است. ElasticNetCV کار انتخاب را برای کاربر انجام خواهد داد.
cv_model = ElasticNetCV(l1_ratio=[.1, .5, .7, .9, .95, .99, 1], eps=1e-3, n_alphas=100, fit_intercept=True,
normalize=True, precompute=’auto’, max_iter=2000, tol=0.0001, cv=6,
copy_X=True, verbose=0, n_jobs=-1, positive=False, random_state=0)
cv_model.fit(X_train, y_train)
print(‘Optimal alpha: %.8f’%cv_model.alpha_)
print(‘Optimal l1_ratio: %.3f’%cv_model.l1_ratio_)
print(‘Number of iterations %d’%cv_model.n_iter_)
کد بالا مربوط به پیادهسازی ElasticNetCV در فایلی با نام ElasticNetCV.py ذخیره میشود.
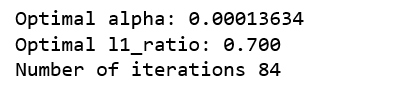
۰< The optimal l1_ratio <1 نشان میدهد که جریمه ترکیبی از L1 و L2 است که ترکیبی از رگرسیونهای لاسو و ستیغی هستند. در ادامه، کد پایتون مورد استفاده برای ارزیابی الگوریتم ارائه شده است.
y_train_pred = cv_model.predict(X_train)
y_pred = cv_model.predict(X_test)
print(‘Train r2 score: ‘, r2_score(y_train_pred, y_train))
print(‘Test r2 score: ‘, r2_score(y_test, y_pred))
train_mse = mean_squared_error(y_train_pred, y_train)
test_mse = mean_squared_error(y_pred, y_test)
train_rmse = np.sqrt(train_mse)
test_rmse = np.sqrt(test_mse)
print(‘Train RMSE: %.4f’ % train_rmse)
print(‘Test RMSE: %.4f’ % test_rmse)
کد بالا در فایلی با عنوان ElasticNetCV_evaluation.py ذخیره میشود.

RMSE، در اینجا در واقع RMSE (سرنامی برای Root Mean Squared Logarithmic Error) است. زیرا، لگاریتم مقادیر گرفته شده است. در ادامه، اهمیت ویژگیها مورد بررسی قرار خواهد گرفت.
feature_importance = pd.Series(index = X_train.columns, data = np.abs(cv_model.coef_))
n_selected_features = (feature_importance>0).sum()
print(‘{0:d} features, reduction of {1:2.2f}%’.format(
n_selected_features,(1-n_selected_features/len(feature_importance))*100))
feature_importance.sort_values().tail(30).plot(kind = ‘bar’, figsize = (12,5));
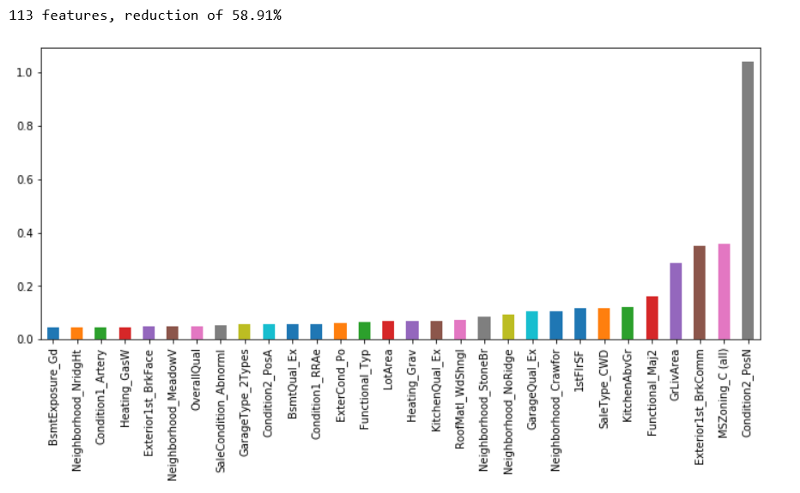
کاهش ٪۵۸.۹۱ از ویژگیها مناسب به نظر میرسد. چهار ویژگی مهمی که توسط ElasticNetCV انتخاب شدهاند عبارتند از: Exterior1st_BrkComm ،MSZoning_C(all) ،Condition2_PosN و GrLivArea. در ادامه، ویژگیهای انتخاب شده در اینجا، با ویژگیهای انتخاب شده با Xgboost مقایسه خواهند شد.
Xgboost
در ادامه، کد پیادهسازی اولین مدل Xgboost ارائه شده است.
xgb_model1 = XGBRegressor()
xgb_model1.fit(X_train, y_train, verbose=False)
y_train_pred1 = xgb_model1.predict(X_train)
y_pred1 = xgb_model1.predict(X_test)
print(‘Train r2 score: ‘, r2_score(y_train_pred1, y_train))
print(‘Test r2 score: ‘, r2_score(y_test, y_pred1))
train_mse1 = mean_squared_error(y_train_pred1, y_train)
test_mse1 = mean_squared_error(y_pred1, y_test)
train_rmse1 = np.sqrt(train_mse1)
test_rmse1 = np.sqrt(test_mse1)
print(‘Train RMSE: %.4f’ % train_rmse1)
print(‘Test RMSE: %.4f’ % test_rmse1)
مدل در فایلی با عنوان xgb_model1.py ذخیره میشود. به نظر میرسد در حال حاضر مدل انتخاب شده توسط ElasticNetCV بهتر است. دومین مدل Xgboost در ادامه پیادهسازی شده است و چندین پارامتر که به نظر میرسد منجر به افزایش صحت مدل میشوند به آن اضافه شده است.
xgb_model2 = XGBRegressor(n_estimators=1000)
xgb_model2.fit(X_train, y_train, early_stopping_rounds=5,
eval_set=[(X_test, y_test)], verbose=False)
y_train_pred2 = xgb_model2.predict(X_train)
y_pred2 = xgb_model2.predict(X_test)
print(‘Train r2 score: ‘, r2_score(y_train_pred2, y_train))
print(‘Test r2 score: ‘, r2_score(y_test, y_pred2))
train_mse2 = mean_squared_error(y_train_pred2, y_train)
test_mse2 = mean_squared_error(y_pred2, y_test)
train_rmse2 = np.sqrt(train_mse2)
test_rmse2 = np.sqrt(test_mse2)
print(‘Train RMSE: %.4f’ % train_rmse2)
print(‘Test RMSE: %.4f’ % test_rmse2)
کد مربوط به دومین مدل Xgboost در فایلی با نام xgb_model2.py ذخیره میشود.

بهبودهای قابل توجهی به وقوع پیوسته است. در سومین Xgboost، یک نرخ یادگیری اضافه میشود که خوشبختانه آن را به مدل صحیحتری مبدل میسازد.
xgb_model3 = XGBRegressor(n_estimators=1000, learning_rate=0.05)
xgb_model3.fit(X_train, y_train, early_stopping_rounds=5,
eval_set=[(X_test, y_test)], verbose=False)
y_train_pred3 = xgb_model3.predict(X_train)
y_pred3 = xgb_model3.predict(X_test)
print(‘Train r2 score: ‘, r2_score(y_train_pred3, y_train))
print(‘Test r2 score: ‘, r2_score(y_test, y_pred3))
train_mse3 = mean_squared_error(y_train_pred3, y_train)
test_mse3 = mean_squared_error(y_pred3, y_test)
train_rmse3 = np.sqrt(train_mse3)
test_rmse3 = np.sqrt(test_mse3)
print(‘Train RMSE: %.4f’ % train_rmse3)
print(‘Test RMSE: %.4f’ % test_rmse3)
کد مدل سوم در فایلی با عنوان xgb_model3.py ذخیره میشود.

متاسفانه بهبودی به وقوع نپیوست. بنابراین، به نظر میرسد xgb_model2 بهترین مدل است. در ادامه، اهمیت ویژگیها بررسی میشود.
from collections import OrderedDict
OrderedDict(sorted(xgb_model2.get_booster().get_fscore().items(), key=lambda t: t[1], reverse=True))

چهار ویژگی مهم انتخاب شده توسط Xgboost عبارتند از: OverallQual ،GrLivArea ،LotArea و TotalBsmtSF. تنها یک ویژگی، یعنی GrLivArea هم توسط ElasticNetCV و هم Xgboost انتخاب شده است. بنابراین، اکنون برخی از ویژگیهای مرتبط انتخاب و مدل مجددا برازش میشود.
most_relevant_features= list( dict((k, v) for k, v in xgb_model2.get_booster().get_fscore().items() if v >= 4).keys())
train_x=df[most_relevant_features]
train_y=df[‘SalePrice’]
X_train, X_test, y_train, y_test = train_test_split(train_x, train_y, test_size = 0.2, random_state = 0)
xgb_model5 = XGBRegressor(n_estimators=1000)
xgb_model5.fit(X_train, y_train, early_stopping_rounds=5,
eval_set=[(X_test, y_test)], verbose=False)
y_train_pred5 = xgb_model5.predict(X_train)
y_pred5 = xgb_model5.predict(X_test)
print(‘Train r2 score: ‘, r2_score(y_train_pred5, y_train))
print(‘Test r2 score: ‘, r2_score(y_test, y_pred5))
train_mse5 = mean_squared_error(y_train_pred5, y_train)
test_mse5 = mean_squared_error(y_pred5, y_test)
train_rmse5 = np.sqrt(train_mse5)
test_rmse5 = np.sqrt(test_mse5)
print(‘Train RMSE: %.4f’ % train_rmse5)
print(‘Test RMSE: %.4f’ % test_rmse5)
کد بالا در فایلی با عنوان xgb_model5.py ذخیره میشود.

بهبود دیگری مجددا به وقوع پیوست.
اگر مطلب بالا برای شما مفید بوده، آموزشهای زیر نیز به شما پیشنهاد میشود:
- مجموعه آموزشهای دادهکاوی و یادگیری ماشین
- مجموعه آموزشهای دادهکاوی یا Data Mining در متلب
- مجموعه آموزشهای هوش مصنوعی
- زبان برنامهنویسی پایتون (Python) — از صفر تا صد
- یادگیری ماشین با پایتون — به زبان ساده
- آموزش یادگیری ماشین با مثالهای کاربردی — مجموعه مقالات جامع وبلاگ فرادرس
- چگونه یک دانشمند داده شوید؟ — راهنمای گامبهگام به همراه معرفی منابع
منبع [+]
مجموعه: داده کاوی, یادگیری ماشینی
