نمونه گیری تامپسون در یادگیری تقویتی — راهنمای کاربردی
«یادگیری تقویتی» (Reinforcement Learning) یکی از شاخههای یادگیری ماشین است که به آن «یادگیری برخط» (Online Learning) نیز گفته میشود. از یادگیری تقویتی برای تصمیمگیری پیرامون آن استفاده میشود که چه اقدامی در زمان t+1 بر اساس آنچه در زمان t به وقوع پیوسته، انجام شود. این مفهوم در برنامههای کاربردی هوش مصنوعی مانند پیادهروی مورد استفاده قرار میگیرد. یک مثال معروف از یادگیری تقویتی، موتور شطرنج است. در اینجا، عامل تصمیم میگیرد که یک مجموعه از حرکات برمبنای حالت محیط اتفاق بیفتد و پاداش در پایان بازی به عنوان «پیروزی» (Win) یا «شکست» (Lose) قابل تعریف است.
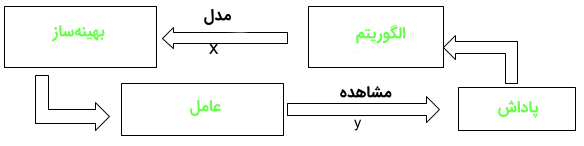
نمونهگیری تامپسون (نمونهگیری پسین یا نمونهگیری تطبیق احتمالات) الگوریتمی برای انتخاب اقداماتی است که به معضل اکتشاف-بهرهبرداری (Exploration-Exploitation Dilemma) در «مسئله راهزن چند دست» (Multi-Armed Bandit Problem | مساله ماشینهای بازی اهرمی با چند بازو) میپردازد. اقدامات چندین بار انجام میشوند و به آنها اکتشاف گفته میشود. در این راستا، از اطلاعات آموزشی استفاده میشود که به جای دستورالعملها با دادن اقدامات صحیح، اقدامات انجام شده را ارزیابی میکند.
این همان چیزی است که نیاز برای اکتشاف فعالانه را برای جستجوی پاداش و خطای صریح برای رفتار خوب ایجاد میکند. بر مبنای نتایج این اقدامات، پاداشها (۱) یا خطاها (۰) برای آن اقدام به ماشین داده میشوند. اقدامات بعدی به منظور بیشینه کردن پاداش که کارایی آتی را بیشینه میکند، انجام میشوند.
رباتی مفروض است که باید چندین قوطی را بردارد و آنها را در کانتینر قرار دهد. هر بار که ربات قوطی را داخل کانتینر قرار میدهد، گامهای دنبال شده را به خاطر میسپارد و خود را برای انجام سریعتر و صحیحتر وظیفه، آموزش میدهد (پاداش). اگر ربات قادر به آن نباشد که قوطی را داخل کانتینر قرار دهد، روال را به خاطر نمیسپارد (بنابراین، سرعت و کارایی بهبودی پیدا نمیکند) و به عنوان پنالتی در نظر گرفته میشود.
نمونهگیری تامپسون مزیت گرایش به کاهش جستجو را همگام با دریافت اطلاعات بیشتر به همراه دارد که موازنه مطلوب در مسئله را تقلید میکند که در آن، هر میزان اطلاعاتی که در جستجوهای بعدی امکانپذیر است خواسته میشود. بنابراین، این الگوریتم گرایش به آن دارد که هنگامی که دادههای کمی وجود دارد «جستجومحورتر» باشد و هنگامی که دادههای زیادی وجود دارد، «کمتر جستجومحور» باشد.
مسئله راهزن چند دست
مسئله راهزن چند دست،معادل یک ماشین بازی اهرمی با تعداد زیادی بازو است. انتخاب هر اقدام، مانند بازی کردن یکی از اهرمهای ماشین بازی و پاداشها پرداخت برای زدن دکمه برداشت جوایز است (Jackpot). با انجام انتخاب اقدام مکرر، میتوان پیروزیها را با تمرکز اقدامات روی بهترین اهرمها بیشینه کرد. هر ماشینی، پاداش جداگانهای را از توزیع احتمال میانگین پاداش مختص ماشین، فراهم میکند.
بدون آگاهی از این احتمالات، بازیکن باید مجموع پاداشهای دریافتی را از طریق یک توالی از کشیدن بازوها بیشینه کند. در صورتی که بازیکن تخمین ارزشهای اقدامات را حفظ کند، در هر گامی دستکم یک گام وجود دارد که ارزش تخمین زده شده برای آن بالاترین میزان است. به این مورد، اقدام حریصانه گفته میشود. مثالی واقعی از این مسئله، تبلیغاتی است که هنگام مرور یک صفحه وب توسط کاربر، به او نمایش داده میشود. بازوها همان تبلیغات نمایش داده شده به کاربر هستند. در هر دوره n، تبلیغ i پاداش ri(n) ε {۰, ۱}: ri(n)=1 را در صورتی که کاربر روی تبلیغ i کلیک کرده باشد و ۰ را در صورتی که روی تبلیع کلیک نکرده باشد، میدهد. هدف الگوریتم آن است که پاداش را بیشینه کنند. دیگر مثال از این مورد پزشکی است که بین درمانهای تجربی موجود برای یک سری بیمار بسیار وخیم در حال انتخاب است. انتخاب هر اقدام انتخاب یک درمان است و هر پاداش بقا یا بهبود بیمار محسوب میشود. الگوریتم مورد استفاده برای این کار، در ادامه آمده است.
- در هر گام t = 1,…, T، یک بازو از N بازو را بکش
- برای هر بازوی i، پاداش از یک پشتیبانی توزیع ثابت اما ناشناخته [۰,۱] با میانگین μi تولید میشود.
- هدف، بیشینه کردن پاداش است.
- بازوی بهینه: i*=arg miax μi
- خروجی (Regret): زیان ناشی از نکشیدن بازوی بهینه
- بازوی بهینه، بازویی با پاداش مورد انتظار است: Δi = μ* – μi
- بازوی I به تعداد (Ki(T بار در زمان T کشیده شود:
- خروجی مورد انتظار در زمان t،
Regret (T) = ∑i = i* ΔiE[ki(T)]
برخی از کاربردهای عملی آنچه بیان شد، در ادامه بیان شده است.
- سیستم توصیهگر مبتنی بر اقلام نتفلیکس: تصاویر مرتبط با فیلمها/نمایشها به کاربران به شکلی نمایش داده میشود که تمایل بیشتری به تماشای آن داشته باشند.
- معاملات سهام و پیشنهاد قیمت (مناقصه و مزایده): پیشبینی سهام بر مبنای دادههای کنونی بورس
- کنترل چراغ ترافیک: پیشبینی تاخیر در سیگنال
- خودکارسازی در صنعت: رباتها و ماشنیها برای حمل و نقل و تحویل اقلام بدون دخالت انسان
اگر این مطلب برای شما مفید بوده است، آموزشها و مطالب زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای دادهکاوی و یادگیری ماشین
- آموزش یادگیری ماشین
- مجموعه آموزشهای هوش مصنوعی
- نکاتی پیرامون سیستمهای پیشنهادگر — پادکست پرسش و پاسخ
- ساخت سیستم توصیهگر در پایتون — به زبان ساده
- سیستم توصیهگر قیمت با پایتون — راهنمای کاربردی
- ساخت سیستم توصیهگر (Recommender System) فیلم با پایتون — راهنمای جامع و ساده
منبع [+]
مجموعه: مهندسی کامپیوتر, هوش مصنوعی, یادگیری ماشینی
