خواندن دادههای بزرگ در شبیهساز متلب (نسخه ۸)

در این بخش، datastore به عنوان یکی از توانمندیهای جدید شبیهساز متلب R2014b در کار با دادههای بزرگ معرفی میشود.
در این بخش، datastore به عنوان یکی از توانمندیهای جدید شبیهساز متلب R2014b در کار با دادههای بزرگ معرفی میشود.
داده
datastore جهت خواندن دادهای استفاده میشود که برای قرار گرفتن در حافظه بسیار بزرگ است. برای نشان دادن نحوه عملکرد، دادههای آماری وسایل نقلیه ایالت ماساچوست را به عنوان نمونه خواهیم خواند که کاتالوگی از اطلاعات وسایل نقلیه ثبت شده از سال ۲۰۰۸ تا سال ۲۰۱۱ است. این مجموعه داده حاوی اطلاعاتی درباره ماشینهای ثبت شده است. این اطلاعات شامل نوع وسیله، مکان اصلی، مصرف سوخت، و میزان انتشار CO2 میباشند. میتوانید از طریق لینک این دادهها را خوانده و یا حتی آن را برای خودتان دانلود کنید.
Datastore چیست؟
همانطور که اشاره شد، datastore یک شیء (آبجکت) پرکاربرد برای خواندن مجموعه دادههاییست که برای قرار گرفتن در حافظه بسیار بزرگ هستند.
تعریف دادههای ورودی
Datastore میتواند با یک یا مجموعهای از فایلها کار کند. در اینجا ما میخواهیم از روی یک فایل عملیات خواندن را انجام دهیم. نام متغیرها در بالای فایل وجود ندارند و در فایلهای سرآیند جداگانهای به صورتی که در زیر تعریف میشود فهرست شدهاند:
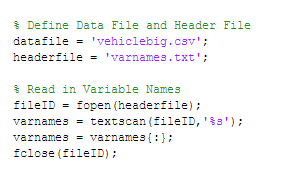
ایجاد DataStore
اکنون میتوانیم datastore خودمان را با دادن نام فایل داده به عنوان ورودی به تابع datastore ایجاد کنیم. همچنین مشخص میکنیم که datastore ما از اولین سطح فایل به عنوان نام متغیرها استفاده نکند. نام این متغیرها را با استفاده از اسامی موجود در فایل ‘varnames.txt’ تنظیم میکنیم.
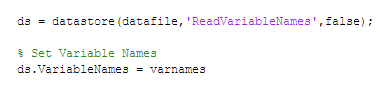

توجه کنید که ما هنوز دادهها را نخواندهایم و تنها یک راه آسان برای دسترسی به آنها از طریق ds، که datastore ماست، ایجاد کردهایم.
مشاهده دادهها
یک نکته جالب در مورد datastore این است که میتوان داده را بدون بارگذاری در حافظه مشاهده کرد. datastore داده را درون یک جدول (table)، که یک نوعِ داده در متلب برای کار با دادههای جدولی است، قرار داده و میخواند.
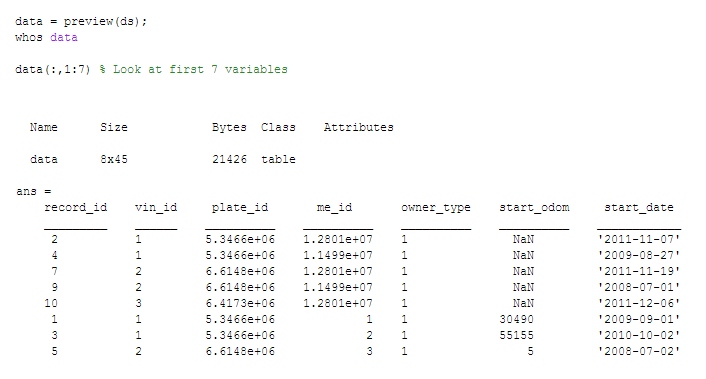
به صورت پیشفرض، datastore مجموعه داده را به صورت ستون به ستون میخواند. datastore در مورد قالب مناسب برای هر ستون (متغیر) از دادهها، حدسی را بر مبنای استدلال و دانش میزند. هرچند ما خودمان نیز میتوانیم زیرمجموعهای از ستونها یا قالبهای مختلف را تعیین کنیم.
انتخاب داده برای ورود (Import)
ما میتوانیم متغیرهای (ستونها) دلخواهمان را با استفاده از ویژگی SelectedVaiableNames مشخص کنیم. در اینجا میخواهیم تنها ۵ ستون از ۴۵ ستون را وارد کنیم:
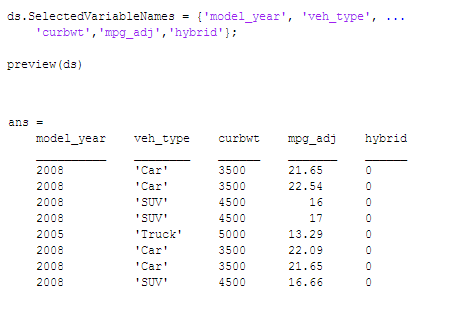
تنظیم قالب متغیرها
ما میتوانیم قالب دادهای که میخواهیم به آن دستیابی داشته باشیم را با استفاده از ویژگی SelectedFromats مشخص کنیم. با استفاده از” %C” میتوانیم مشخص کنیم که نوع وسیله نقلیه به عنوان متغیر دستهبندی وارد شود.

خواندن اولین چانک داده (chunk)
میتوانیم از تابع read برای خواندن یک چانک از داده استفاده کنیم. به صورت پیشفرض، تابع read در هر زمان ۲۰۰۰۰ سطر را میخواند. این مقدار با استفاده از ویژگی RowsPerRead قابل تنظیم است.

بعد از اینکه یک چانک داده را خواندید، میتوانید از تابع hasdata برای دیدن اینکه آیا هنوز داده در دسترس دیگری برای خوانده شدن از datastore وجود دارد یا خیر، استفاده کنید.

با استفاده از hasdata و read درون یک حلقه while در datastore، میتوانید تمام مجموعه داده را به صورت یک تکه در هر زمان بخوانید. ما از یک شمارنده برای محاسبه اینکه چند عملیات خواندن در حلقه ما رخ میدهد، استفاده میکنیم:

با استفاده از reset، میتوانیم شروع به خواندن از ابتدای فایل کنیم:
![]()
اکنون که مقدمات استفاده از datastore را دیدیم، بیایید سه روش مختلف را برای استفاده از datastore در کار با مجموعه دادهای که برای قرار گرفتن در حافظه بسیار بزرگ است، ببینیم.
روش ۱: ستونهای دلخواه از داده را برای استفاده در حافظه بخوانید.
اگر تنها میخواهید ستونهای مشخصی از یک فایل متنی را بخوانید و این ستونها در حافظه جا میشوند، میتوانید از datastore برای وارد کردن این ستونهای دلخواه از فایل متنی استفاده کنید. پس از این کار میتوانید با دادهها به صورت مستقیم در حافظه کار کنید. در این مثال ما تنها به سال مدل و نوع ماشینهایی که ثبت شدهاند علاقهمندیم. میتوانیم به جای read از readall برای وارد کردن تمام دادههای انتخابی به جای تنها یک چانک از آن در هر زمان، استفاده کنیم.
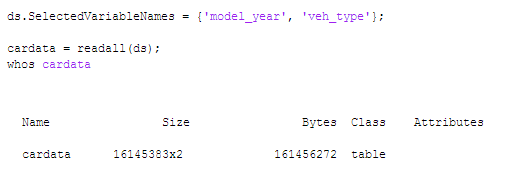
اکنون که دادههایتان را در MATLAB وارد کردید، میتوانید با آنها همچون وقتی که با دادههای متلب کار میکنید، کار کنید. برای این مثال ما از تابع جدید histogram که در نسخه R2014b ارائه شده است جهت انداختن نگاهی به توزیع سال تولید مدلهای وسایل نقلیه ثبت شده، استفاده میکنیم:

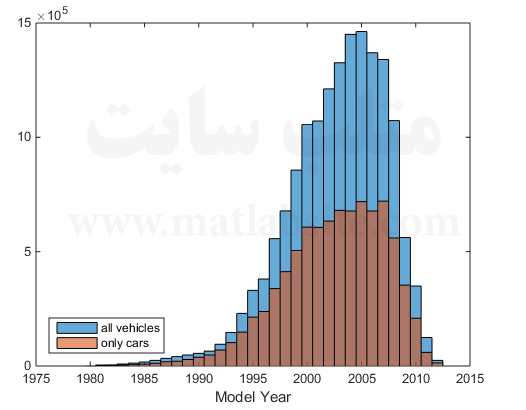
روش ۲: داده را فیلتر کنید و زیرمجموعه حاصل را برای استفاده در حافظه به کار بگیرید.
یک روش دیگر برای کم کردن داده، فیلتر کردن هر چانک آن در هر زمان است. با استفاده از datastore میتوانید یک چانک از داده را خوانده و تنها اطلاعاتی که در آن چانک به آنها نیاز دارید را نگه دارید. سپس میتوانید این فرایند را چانک به چانک انجام دهید تا زمانی که به پایان فایل برسید. در نهایت زیرمجموعهای از دادهها که به آنها نیاز دارید را خواهید داشت.
در این جا میخواهیم زیرمجموعهای از دادهها را برای ماشینهایی که در سال ۲۰۱۱ ثبت شدهاند استخراج کنیم. متغیرهای جدیدی که میخواهیم بارگزاری کنیم (برای مثال q1_2011) شامل مقدار یک یا صفر هستند. یکها نشاندهنده ثبتهای معتبر ماشین در آن دوره زمانی میباشند. بنابراین، تنها ردیفهایی که حاوی ثبتهای معتبر در سال ۲۰۱۱ هستند را ذخیره کرده و باقی را حذف میکنیم:

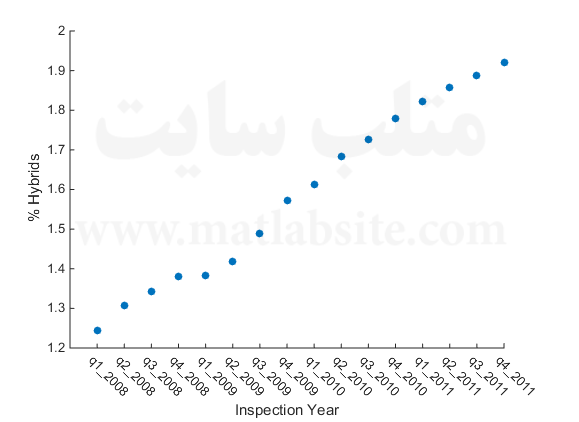
روش ۳: تحلیلی را روی چانکهای داده انجام بدهید و نتایج را ترکیب کنید.
اما چه باید بکنیم اگر نتوانیم زیرمجموعهای از داده که به تحلیل آن علاقهمندیم را در حافظه ضبط کنیم؟ میتوانیم در عوض هر بخش از داده را در هر زمان پردازش کنیم و سپس نتایج میانی را برای رسیدن به یک نتیجه نهایی ترکیب کنیم. برای این مورد، بیایید به درصد ماشینهای هیبریدی ثبت شده در هر سه ماه از سال نگاهی بیندازیم (نسبت به تعداد کل ماشینهای ثبت شده). بنابراین، باید تعداد کل ماشینهای ثبت شده در هر دوره سه ماهه از سال را به همراه تعداد ماشینهای هیبریدی ثبت شده در این بازه، محاسبه کنیم. سپس وقتی تمام مجموعه داده را خواندیم، درصد نهایی را محاسبه میکنیم:


گسترش کاربرد Datastore
شما همچنین میتوانید از datastore به عنوان اولین گام برای ایجاد و اجرای الگوریتمهای MapReduce در MATLAB استفاده کنید.
مجموعه: متلب
