آموزش یادگیری تقویتی (Reinforcement Learning)
هوش مصنوعی، علم مطالعه و بررسی ماشینهایی است که رفتار هوشمندانه دارند. مفهوم هوشمندی، چیزی است که به سختی قابل تعریف است. اما معمولا هوشمندی با توانایی یادگیری از طریق تجربه، مرتبط دانسته میشود. یادگیری ماشینی، زمینهای مطالعاتی در هوش مصنوعی است که به دنبال ایجاد عاملهایی همچون برنامههای کامپیوتری است که بتوانند با استفاده از تجربیات خود یاد بگیرند. ایدهی ایجاد ماشینهایی که رفتار هوشمندانهی انسان را تقلید میکنند، بدون الهام گرفتن از هوشمندی انسانها، هیچگاه کامل نخواهد بود و به ثمر نخواهد نشست.
هوش مصنوعی و یادگیری ماشینی
هوش مصنوعی، علم مطالعه و بررسی ماشینهایی است که رفتار هوشمندانه دارند. مفهوم هوشمندی، چیزی است که به سختی قابل تعریف است. اما معمولا هوشمندی با توانایی یادگیری از طریق تجربه، مرتبط دانسته میشود. یادگیری ماشینی، زمینهای مطالعاتی در هوش مصنوعی است که به دنبال ایجاد عاملهایی همچون برنامههای کامپیوتری است که بتوانند با استفاده از تجربیات خود یاد بگیرند. ایدهی ایجاد ماشینهایی که رفتار هوشمندانهی انسان را تقلید میکنند، بدون الهام گرفتن از هوشمندی انسانها، هیچگاه کامل نخواهد بود و به ثمر نخواهد نشست.
با گذشت زمان، هوش مصنوعی و یادگیری ماشینی در حال تبدیل شدن به رشتههای مهندسی هستند و ندرتا به عنوان علوم طبیعی به آنها نگریسته میشود. در عصر صنعت، ما به دنبال ساختن ماشینهایی بودیم که برای ما کار فیزیکی انجام دهند. اما در عصر اطلاعات، ما در پی ساختن ماشینهایی هستیم که برای ما فکر کنند. دشواریهای ایجاد چنین ماشینهایی، بسیار زیاد است. زیرا ما اطلاع دقیقی از منبع هوشمندی خودمان نداریم و طبعا نمیتوانیم به راحتی، ماشینهایی هوشمند و نظیر خودمان را بسازیم.
مهم ترین کاری که غالبا یک سیستم هوشمند انجام می دهد، امکان یادگیری است و اگر یک سیستم هوشمند بتواند یادگیری انسان را شبیه سازی کند، تا حدود زیادی در پیاده سازی هوش مصنوعی، موفق خواهد بود. هدف اصلی از یادگیری یافتن شیوهای برای عملکرد در حالات مختلف است که این شیوه در مقایسه با سایرین، با در نظر گرفتن معیارهایی، بهتر است. معمولا این شیوهی عملکرد، از نظر ریاضی، به صورت نگاشتی از فضای حالات به فضای اعمال، قابل بیان است. هنگامی میتوان گفت یادگیری اتفاق افتاده است که، عاملی بر اساس تجربیاتی که کسب میکند به نحوی دیگر، و به احتمال زیاد بهتر، عمل کند. در این صورت میبایست نحوهی عملکرد عامل در اثر کسب اطلاعات جدید، متفاوت از نحوهی عملکرد در زمان قبل از کسب این اطلاعات و تجارب باشد.
انواع روش های یادگیری ماشینی
رویکردهای مهم یادگیری ماشین، در چند دسته عمده قابل تقسیم بندی هستند، که فهرست آن ها در ادامه آمده است:
- یادگیری نظارت شده (با ناظر): این نوع یادگیری، مرسوم ترین نوع یادگیری در سیستم آموزشی انسان هاست. اما با این حال، چیزی نیست که در طبیعت رایج باشد. در این نوع یادگیری، حضور یک خبره، معلم، ناظر و یا داده هایی حاوی دانش وی، ضروری است.
- یادگیری غیر نظارت شده (بدون ناظر): این شیوه یادگیری، در بسیاری از موجودات و در برهه های مختلف زندگی انسان ها دیده می شود و یکی از سخت ترین نوع مسائل یادگیری است. در این نوع از یادگیری، نیازی به حضور ناظر، معلم یا خبره نیست.
- یادگیری نیمه نظارت شده: ترکیبی از دو ایده نظارت شده و غیر نظارت شده است، که در کنار استفاده از تجارب ارائه شده توسط ناظر، توانایی استفاده از رویکردهای غیر نظارت شده نیز مد نظر قرار گرفته است.
- یادگیری تقویتی: در این نوع از یادگیری، برای تشخیص درستی یا نادرستی روند یادگیری، از سیگنال ها و اندازه گیری های ضمنی برای یادگیری غیر مستقیم استفاده می کنند. به عبارتی، دانش فعلی ذخیره شده، توسط سیگنال های پاداش یا جریمه، تقویت (تضعیف) می شود.
یادگیری تقویتی
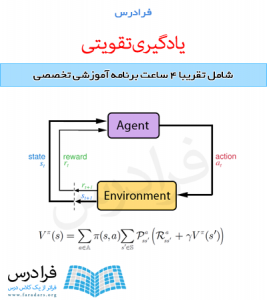
تفاوت اصلی میان یادگیری نظارت شده و یادگیری تقویتی این است که در یادگیری تقویتی، هیچ گاه به عامل گفته نمیشود که عمل صحیح در هر وضعیت چیست، و فقط به وسیلهی معیاری، به عامل گفته میشود که یک عمل چقدر خوب و چقدر بد است. این وظیفهی عامل یادگیرنده است که با در دست داشتن این اطلاعات، یاد بگیرد که بهترین عمل در هر وضعیت کدام است. این موضوع، بخشی از نقاط قوت خاص یادگیری تقویتی است. از این طریق، مسائل پیچیدهی تصمیمگیری در اغلب اوقات میتوانند با فراهم کردن کمترین میزان اطلاعات مورد نیاز برای حل مسأله، حل شوند. در بسیاری از حیوانات، یادگیری تقویتی، تنها شیوهی یادگیری مورد استفاده است. همچنین یادگیری تقویتی، بخشی اساسی از رفتار انسانها را تشکیل میدهد. هنگامی که دست ما در مواجهه با حرارت میسوزد، ما به سرعت یاد میگیریم که این کار را بار دیگر تکرار نکنیم. لذت و درد مثالهای خوبی از پاداشها هستند که الگوهای رفتاری ما و بسیاری از حیوانات را تشکیل میدهند. در یادگیری تقویتی، هدف اصلی از یادگیری، انجام دادن کاری و یا رسیدن به هدفی است، بدون آنکه عامل یادگیرنده، با اطلاعات مستقیم بیرونی تغذیه شود.
آنچه در این فرادرس خواهید دید
مجموعه فرادرس های یادگیری تقویتی (Reinforcement Learning) شامل بررسی کامل و اصولی مباحث یادگیری تقویتی و الگوریتم های مختلف آن است و در کنار تشریح کامل مبانی تئوری این رویکردها، پیاده سازی عملی و گام به گام این روش ها با استفاده از متلب، مد نظر قرار گرفته است.
مطالب ارائه شده در این مجموعه آموزش، با در نظر گرفتن کاربرد روش های یادگیری تقویتی در حوزه های مختف مهندسی و علمی بیان شده اند و از این نظر، برای طیف وسیعی از دانشجویان (به ویژه دانشجویان مهندسی کنترل و هوش مصنوعی) قابل استفاده هستند.
مدرس این مجموعه آموزش، دکتر سیدمصطفی کلامی هریس (دکترای تخصصی مهندسی کنترل از دانشگاه صنعتی خواجه نصیرالدین طوسی) است. یکی از زمینه های تحقیقاتی مهم ایشان، به ویژه در مقطع کارشناسی ارشد، موضوع یادگیری تقویتی بوده است و ارائه و اثبات قضیه ای جدید در خصوص یادگیری تقویتی در محیط های جدولی و ارتباط آن با سیستم های کنترل دیجیتال، از دستاوردهای پژوهشی ایشان در مقطع کارشناسی ارشد بوده است.
به طور ویژه در این دوره آموزشی، در خصوص ارتباط و تناظر میان یادگیری تقویتی و سیستم های کنترل بهینه بحث شده است، که موجب ایجاد نگرشی کلی نسبت به این دو موضوع خواهد شد.
آموزش یادگیری تقویتی یا Reinforcement Learning — کلیک کنید (+)
سرفصل های این دوره آموزشی
فهرست مطالب و سرفصل های مطرح شده در این مجموعه آموزشی، در ادامه آمده است:
- درس یکم: مفاهیم بنیادین یادگیری تقویتی
- یادگیری ماشین و روش های آن
- یادگیری تقویتی چیست؟
- مثال هایی از یادگیری تقویتی
- مروری بر تاریخچه یادگیری تقویتی
- نام های دیگر یادگیری تقویتی
- درس دوم: ماشین های بازی اهرمی
- مسأله ماشین های بازی اهرمی با چند بازو
- روش های مبتنی بر ارزش عمل
- رویکردهای انتخاب عمل مناسب
- روش انتخاب Softmax
- جستجو یا Exploration
- استخراج (بهره برداری) یا Exploitation
- مباحث تکمیلی در خصوص مسائل n-Armed Bandit
- پیاده سازی عملی روش های مورد بحث
- درس سوم: مسأله یادگیری تقویتی
- تعریف عمومی مسأله یادگیری تقویتی
- نحوه ارتباط عامل با محیط
- تعاریف و مفاهیم پایه
- سیگنال پاداش و جریمه
- اهداف یک عامل
- بازده و سود
- خاصیت مارکوف در سیستم ها
- فرایندهای تصمیم گیری مارکوف یا MDP
- تابع ارزش
- معیار بهینگی مقدار تابع ارزش
- درس چهارم: برنامه ریزی پویا یا Dynamic Programming (الف)
- روش های یادگیری مبتنی بر جدول های عمل-ارزش
- مفهوم سیاست یا Policy
- الگوریتم های پایه در برنامه ریزی پویا
- ارزیابی سیاست یا Policy Evaluation
- بهبود سیاست یا Policy Improvment
- حلقه تکرار سیاست یا Policy Iteration
- حلقه تکرار ارزش یا Value Iteration
- قضایای بلمن
- عملگر بلمن
- پیاده سازی عملی روش های مورد بحث
- درس پنجم: برنامه ریزی پویا یا Dynamic Programming (ب)
- برنامه ریزی پویای ناهمزمان (غیر سنکرون)
- حلقه تکرار سیاست تعمیم یافته
- بررسی میزان کارایی برنامه ریزی پویا
- پیاده سازی عملی روش های مورد بحث
- درس ششم: روش های مونت کارلو یا Monte Carlo (الف)
- مشکلات و محدودیت های موجود در برنامه ریزی پویا
- ارزیابی سیاست مبتنی بر رویکرد مونت کارلو
- تخمین ارزش اعمال (اکشن ها) با رویکرد مونت کارلو
- کنترل مونت کارلو یا Monte Carlo Control
- کنترل مونت کارلو با سیاست فعال (On-Policy)
- پیاده سازی عملی روش های مورد بحث
- درس هفتم: روش های مونت کارلو یا Monte Carlo (ب)
- ارزیابی یک سیاست در هنگام پیروی از سیاست دیگر
- ارزیابی سیاست مبتنی بر رویکرد مونت کارلو با سیاست غیر فعال (Off-Policy)
- کنترل مونت کارلو با سیاست غیر فعال (Off-Policy)
- پیاده سازی افزایشی
- پیاده سازی عملی روش های مورد بحث
- درس هشتم: یادگیری مبتنی بر تفاضل مقطعی (الف)
- پیش بینی مبتنی بر تفاضل مقطعی یا Temporal Difference
- نقاط قوت روش های تفاضل مقطعی
- بهینگی رویکرد TD صفر یا TD(0)
- الگوریتم SARSA یا کنترل TD با سیاست فعال (On-Policy)
- پیاده سازی الگوریتم SARSA در متلب
- کاربرد SARSA در کنترل
- درس نهم: یادگیری مبتنی بر تفاضل مقطعی (ب)
- الگوریتم یادگیری Q یا Q-Learning یا کنترل TD با سیاست غیر فعال (Off-Policy)
- پیاده سازی الگوریتم Q-Learning در متلب
- کاربرد Q-Learning در کنترل
- مروری بر الگوریتم سیستم مورچگان به عنوان نسخه ای از Q-Learning
- مباحث تکمیلی بر روی روش های TD
- درس دهم: یادگیری مبتنی بر تفاضل مقطعی (پ)
- الگوریتم های TD با پیش بینی یا TD(λ)
- نگرش پیشرو (مستیقم) در TD(λ)
- نگرش پسرو (معکوس) در TD(λ)
- یکسانی نگرش های پیشرو و پسرو
- الگوریتم SARSA(λ)
- الگوریتم یادگیری Q(λ)
- مقدار λ متغیر
- درس یازدهم: روش های تقریب و یادگیری تابع ارزش
- تقریب تابع ارزش با سیاست فعال
- برنامه ریزی پویای تقریبی
- رویکردهای تقریب تابع یا Function Approximation
- استفاده از کمترین مربعات برای تقریب تابع ارزش
- مدل های خطی و شبکه های عصبی برای تقریب تابع ارزش
- روش های مبتنی بر گرادیان نزولی
- پیاده سازی کنترل با استفاده از تقریب تابع ارزش
- تقریب تابع ارزش با سیاست غیر فعال
- درس دوازدهم: یادگیری و بهینه سازی همزمان (الف)
- مروری بر استراتژی های یادگیری و بهینه سازی همزمان
- تقریب حلقه تکرار ارزش با استفاده از جدول ارجاع
- تقریب Q-Learning با استفاده از جدول ارجاع
- تقریب با استفاده از مدل های خطی و شبکه های عصبی مصنوعی
- درس سیزدهم: یادگیری و بهینه سازی همزمان (ب)
- تقریب حلقه تکرار سیاست
- ساختار و الگوی عامل-نقاد یا Actor-Critic
- برنامه ریزی خطی و توابع پایه
- حلقه تکرار سیاست تقریبی با روش های رگرسیون مبتین بر توابع پایه
- تقریب افق محدود برای کاربردهای حالت دائم
- پیاده سازی کنترل بهینه آنلاین با یادگیری تقویتی
- درس چهاردهم: مسائل تخصیص منابع پویا
- تعریف عمومی مسائل تخصیص منابع پویا (Dynamic Resource Allocation)
- روش های تقریب تابع ارزش برای مسائل تخصیص منابع پویا
- بررسی و حل انواع مسائل تخصیص منابع پویا
مجموعه: مهندسی کنترل, هوش محاسباتی, یادگیری ماشینی
