درخت تصمیم (Decision Tree) با پایتون — راهنمای کاربردی
«درخت تصمیم» (Decision Tree) از جمله الگوریتمهای «یادگیری ماشین» (Machine Learning) است که هم برای مسائل «دستهبندی» (Classification) و هم مسائل «رگرسیون» (Regression) مورد استفاده قرار میگیرد. البته، الگوریتم درخت تصمیم بیشتر در مسائل دستهبندی استفاده میشود.
این مدل، یک نمونه را دریافت میکند، درخت را میپیماید و ویژگیهای مهم را با یک عبارت شرطی تعیین شده، مقایسه میکند. اینکه آیا در شاخه فرزند سمت چپ قرار بگیرد و یا سمت راست، بستگی به نتیجه حاصل از بررسی عبارت شرطی دارد. معمولا، یک ویژگی مهمتر به ریشه نزدیکتر است.
درخت تصمیم، یک الگوریتم «یادگیری ماشین» (Machine Learning) است که هم روی متغیرهای وابسته «پیوسته» (Continuous) و هم «طبقهای» (Categorical) قابل اعمال است. در اینجا، جمعیت به دو یا تعداد بیشتری مجموعه همگن تقسیم میشود. در ادامه، کد پیادهسازی این الگوریتم در پایتون ارائه شده است.
قطعه کد ۱:
>>> from sklearn.cross_validation import train_test_split
>>> from sklearn.tree import DecisionTreeClassifier
>>> from sklearn.metrics import accuracy_score
>>> from sklearn.metrics import classification_report
>>> def importdata(): #Importing data
balance_data=pd.read_csv(‘https://archive.ics.uci.edu/ml/machine-learning-‘+
‘databases/balance-scale/balance-scale.data’,
sep= ‘,’, header = None)
print(len(balance_data))
print(balance_data.shape)
print(balance_data.head())
return balance_data
>>> def splitdataset(balance_data): #Splitting data
x=balance_data.values[:,1:5]
y=balance_data.values[:,0]
x_train,x_test,y_train,y_test=train_test_split(
x,y,test_size=0.3,random_state=100)
return x,y,x_train,x_test,y_train,y_test
>>> def train_using_gini(x_train,x_test,y_train): #Training with giniIndex
clf_gini = DecisionTreeClassifier(criterion = “gini”,
random_state = 100,max_depth=3, min_samples_leaf=5)
clf_gini.fit(x_train,y_train)
return clf_gini
>>> def train_using_entropy(x_train,x_test,y_train): #Training with entropy
clf_entropy=DecisionTreeClassifier(
criterion = “entropy”, random_state = 100,
max_depth = 3, min_samples_leaf = 5)
clf_entropy.fit(x_train,y_train)
return clf_entropy
>>> def prediction(x_test,clf_object): #Making predictions
y_pred=clf_object.predict(x_test)
print(f”Predicted values: {y_pred}”)
return y_pred
>>> def cal_accuracy(y_test,y_pred): #Calculating accuracy
print(confusion_matrix(y_test,y_pred))
print(accuracy_score(y_test,y_pred)*100)
print(classification_report(y_test,y_pred))
>>> data=importdata()
خروجی ۱:
۶۲۵
(۶۲۵, ۵)
۰ ۱ ۲ ۳ ۴
۰ B 1 1 1 1
۱ R 1 1 1 2
۲ R 1 1 1 3
۳ R 1 1 1 4
۴ R 1 1 1 5
قطعه کد ۲:
>>> x,y,x_train,x_test,y_train,y_test=splitdataset(data)
>>> clf_gini=train_using_gini(x_train,x_test,y_train)
>>> clf_entropy=train_using_entropy(x_train,x_test,y_train)
>>> y_pred_gini=prediction(x_test,clf_gini)

قطعه کد ۳:
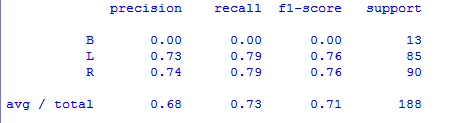
>>> cal_accuracy(y_test,y_pred_gini)
خروجی ۳:
[[ ۰ ۶ ۷] [ ۰ ۶۷ ۱۸] [ ۰ ۱۹ ۷۱]] ۷۳٫۴۰۴۲۵۵۳۱۹۱۴۸۹۳
قطعه کد ۴:
>>> y_pred_entropy=prediction(x_test,clf_entropy)
قطعه کد ۵:
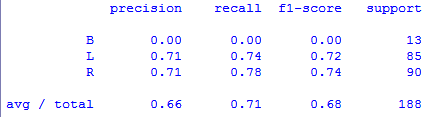
>>> cal_accuracy(y_test,y_pred_entropy)
[[ ۰ ۶ ۷] [ ۰ ۶۳ ۲۲] [ ۰ ۲۰ ۷۰]] ۷۰٫۷۴۴۶۸۰۸۵۱۰۶۳۸۳
اگر نوشته بالا برای شما مفید بوده، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای آمار، احتمالات و دادهکاوی
- آموزش دادهکاوی یا Data Mining در متلب
- مجموعه آموزشهای یادگیری ماشین و بازشناسی الگو
- دادهکاوی (Data Mining) — از صفر تا صد
- یادگیری علم داده (Data Science) با پایتون — از صفر تا صد
- زبان برنامهنویسی پایتون (Python) — از صفر تا صد
مجموعه: داده کاوی, یادگیری ماشینی
