دسته بندی داده ها با ماشین بردار پشتیبان (SVM) — به زبان ساده
در «یادگیری ماشین» (Machine Learning) و «دادهکاوی» (Data Mining)، الگوریتم «ماشین بردار پشتیبان» (Support Vector Machines | SVM)، از جمله روشهای «یادگیری نظارت شده» (Supervised Learning) محسوب میشود که برای انجام «دستهبندی» (Classification) و «تحلیل رگرسیون» (Regression) روی دادهها مورد استفاده قرار میگیرد. ماشین بردار پشتیبان، یک دستهبند متمایز کننده است که میتواند صفحه بهینهای که دستههای گوناگون دادهها را از هم جدا میسازد، پیدا کند.
ماشین بردار پشتیبان (SVM) چیست؟
مدل SVM، ارائهای از نمونه دادهها به صورت نقاط داده در فضای n-بُعدی ارائه میکند. بنابراین، نمونهها در دستههای گوناگونی قرار میگیرند که با یک شکاف که تا حد ممکن بزرگ است، جداسازی میشوند. علاوه بر انجام دستهبندی خطی، SVM میتواند دستهبندی غیر خطی را نیز به صورت کارایی انجام دهد و به طور ضمنی، ورودیها را به فضای داده ابعاد بالا نگاشت کند.
SVM چه کار میکند؟
الگوریتم ماشین بردار پشتیبان (SVM)، یک مجموعه از نمونههای آموزش را که برچسبگذاری شدهاند و هر یک متعلق به یک دسته خاص هستند، دریافت میکند. سپس، SVM طی فرایند آموزش، مدلی را میسازد که نمونههای جدید را به یک دسته یا دسته دیگری تخصیص میدهد؛ این امر آن را به یک دستهبند خطی دودویی غیر احتمالی مبدل میسازد. برای مطالعه بیشتر در این رابطه، مطالعه مطلب «ماشین بردار پشتیبان — به همراه کدنویسی پایتون و R» توصیه میشود.
در ادامه، مثالی ارائه شده است که در آن، الگوریتم ماشین بردار پشتیبان (SVM) روی یک مجموعه داده سرطان [+] که در سایت دانشگاه کالیفرنیا در ارواین قرار دارد، اعمال شده است. در کد پایتون زیر، از کتابخانههای «نامپای» (NumPy)، «پانداس» (Pandas)، (متپلاتلیب) (Matplot-lib) و «سایکیت-لرن» (Scikit-Learn) استفاده شده است. اما پیش از مثال اصلی، یک مثال ساده از SVM ارائه میشود.
مثال ۱
ابتدا، نیاز به ساخت مجموعه داده است.
# importing scikit learn with make_blobs
from sklearn.datasets.samples_generator import make_blobs
# creating datasets X containing n_samples
# Y containing two classes
X, Y = make_blobs(n_samples=500, centers=2,
random_state=0, cluster_std=0.40)
# plotting scatters
plt.scatter(X[:, 0], X[:, 1], c=Y, s=50, cmap=’spring’);
plt.show()
خروجی:
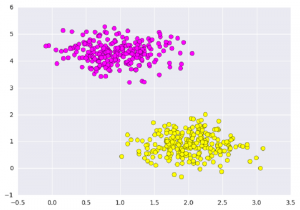
کاری که ماشین بردار پشتیبان در اینجا انجام میدهد، ترسیم یک خط بین دو دسته نیست؛ بلکه، در نظر گرفتن ناحیهای با پهنای مشخص است که دستههای داده را از یکدیگر متمایز میکند. در ادامه، مثالی از چگونگی به نظر رسیدن این ناحیه، ارائه شده است.
# creating line space between -1 to 3.5
xfit = np.linspace(-1, 3.5)
# plotting scatter
plt.scatter(X[:, 0], X[:, 1], c=Y, s=50, cmap=’spring’)
# plot a line between the different sets of data
for m, b, d in [(1, 0.65, 0.33), (0.5, 1.6, 0.55), (-0.2, 2.9, 0.2)]:
yfit = m * xfit + b
plt.plot(xfit, yfit, ‘-k’)
plt.fill_between(xfit, yfit – d, yfit + d, edgecolor=’none’,
color=’#AAAAAA’, alpha=0.4)
plt.xlim(-1, 3.5);
plt.show()
خروجی:
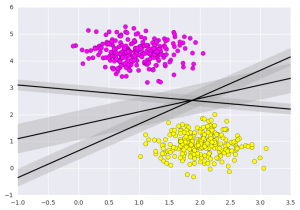
این بینشی است که ماشین بردار پشتیبان ارائه میکند. SVM در واقع، یک مدل متمایز کننده خطی را که عمود بر فاصله بین مجموعه دادهها است، بهینه میکند.
مثال ۲
اکنون، میتوان دستهبند را با استفاده از «مجموعه داده آموزش» (Train Data Set) مربوط به سرطان، آموزش داد. پیش از آموزش دادن مدل، باید مجموعه داده سرطان را به صورت یک فایل CSV «وارد» (ایمپورت | import) کرد که در آن دو ویژگی از میان کل ویژگیها آموزش داده میشوند.
# importing required libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# reading csv file and extracting class column to y.
x = pd.read_csv(“C:\…\cancer.csv”)
a = np.array(x)
y = a[:,30] # classes having 0 and 1
# extracting two features
x = np.column_stack((x.malignant,x.benign))
x.shape # 569 samples and 2 features
print (x),(y)
خروجی:
[[ ۱۲۲٫۸ ۱۰۰۱٫ ]
[ ۱۳۲٫۹ ۱۳۲۶٫ ]
[ ۱۳۰٫ ۱۲۰۳٫ ]
…,
[ ۱۰۸٫۳ ۸۵۸٫۱ ]
[ ۱۴۰٫۱ ۱۲۶۵٫ ]
[ ۴۷٫۹۲ ۱۸۱٫ ]]
array([ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
۰٫, ۰٫, ۰٫, ۰٫, ۰٫, ۰٫, ۱٫, ۱٫, ۱٫, ۰٫, ۰٫, ۰٫, ۰٫,
۰٫, ۰٫, ۰٫, ۰٫, ۰٫, ۰٫, ۰٫, ۰٫, ۰٫, ۰٫, ۰٫, ۱٫, ۰٫,
۰٫, ۰٫, ۰٫, ۰٫, ۰٫, ۰٫, ۰٫, ۱٫, ۰٫, ۱٫, ۱٫, ۱٫, ۱٫,
۱٫, ۰٫, ۰٫, ۱٫, ۰٫, ۰٫, ۱٫, ۱٫, ۱٫, ۱٫, ۰٫, ۱٫, ….,
۱٫])
اکنون، یک دستهبند ماشین بردار پشتیبان برای این نقاط برازش داده میشود. با وجود آنکه جزئیات ریاضی «مدل درستنمایی» (Likelihood Model) جذاب هستند، اما پرداختن به آنها از حوصله این بحث خارج است. بنابراین، با الگوریتم سایکیت-لرن به صورت یک جعبه سیاه برخورد میشود که میتواند وظیفه مورد نظر کاربر را انجام دهد.
# import support vector classifier
from sklearn.svm import SVC # “Support Vector Classifier”
clf = SVC(kernel=’linear’)
# fitting x samples and y classes
clf.fit(x, y)
پس از انجام برازش، مدل میتواند برای پیشبینی مقادیر جدید مورد استفاده قرار بگیرد.
clf.predict([[120, 990]])
clf.predict([[85, 550]])
خروجی:
array([ 0.])
array([ 1.])
در ادامه، نمودار مربوط به خروجی کد بالا ارائه شده است.
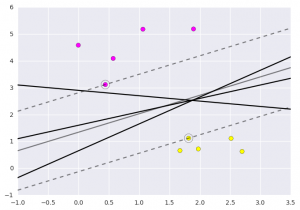
مشاهدات بالا، حاصل تحلیل دادههای دریافتی و استفاده از روشهای پیشپردازش برای به دست آوردن صفحه بهینه با استفاده از تابع matplotlib است.
اگر نوشته بالا برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای دادهکاوی و یادگیری ماشین
- مجموعه آموزشهای دادهکاوی یا Data Mining در متلب
- مجموعه آموزشهای آمار و احتمالات
- زبان برنامهنویسی پایتون (Python) — از صفر تا صد
- آموزش یادگیری ماشین با مثالهای کاربردی — مجموعه مقالات جامع وبلاگ فرادرس
- روش انتخاب الگوریتم دادهکاوی — راهنمای کاربردی
منبع [+]
مجموعه: برنامه نویسی, داده کاوی, یادگیری ماشینی

سلام، اگه داده ها چند بعدی باشه باید ،برای svm حتما باید اونا رو به فضای دو بعدی کاهش بعد بدهیم ؟؟؟
اگر جواب منفی است و داد ها با همون ابعاد هم با svm کار می کنند.برای رسم شکل آنها باید چهکار کرد ؟