دسته بندی گل ها با استفاده از یادگیری انتقال — به زبان ساده
«یادگیری انتقال» (Transfer Learning) یک روش «یادگیری ماشین» (Machine Learning) است که هدف آن کمک به ارتقای پیشبینیهای یک مقدار هدف با استفاده از دانشی است که از مدل آموزش دیده پیشین حاصل شده است. نکته جالب توجه پیرامون این روش یادگیری ماشین آن است که مدل پیشین میتواند با مجموعه داده متفاوتی آموزش داده شده باشد و هدف اصلی آن حل مسأله دیگری باشد. در این مطلب، برخی از مفاهیم «یادگیری عمیق» (Deep Learning) و یادگیری انتقال به منظور پیشبینی دستههای گل بریتانیایی مورد استفاده قرار خواهد گرفت.
مجموعه داده مورد استفاده
دادههای مورد استفاده در این پروژه از «ویژوال جئومتریک گروپ» (Visual Geometric Group) از دانشگاه آکسفورد برداشته شده و از این مسیر [+] در دسترس است.
این مجموعه داده حاوی ۱۰۲ دسته از گلهایی است که معمولا در انگلستان رشد میکنند. چنانکه در منبع اصلی شرح داده شده است، هر دسته گل شامل ۴۰ تا ۲۵۸ تصویر است.
چارچوب یادگیری عمیق
یادگیری عمیق برپایه چیزی که «شبکه عصبی» (Neural Network) نامیده میشود ساخته شده است. یک شبکه ساده اساسا شامل ورودیهایی است که وزندهی شدهاند و از طریق یک تابع فعالسازی پاس داده میشوند. شمای سادهای که در زیر آورده، معمولا یک «واحد» (Unit) نامیده میشود و میتواند به صورتی که در شکل زیر نمایش داده شده، به تصویر کشیده شود.
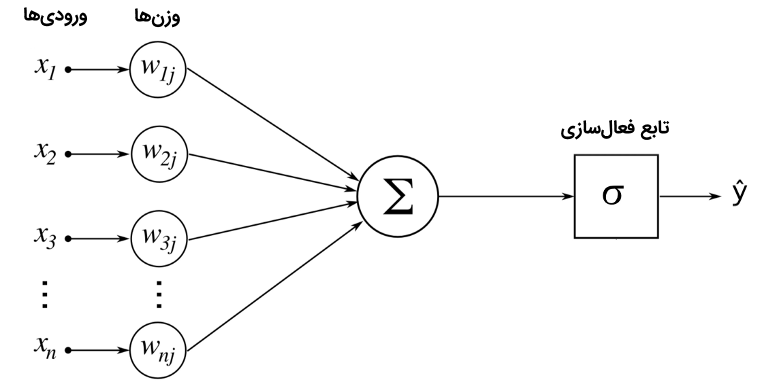
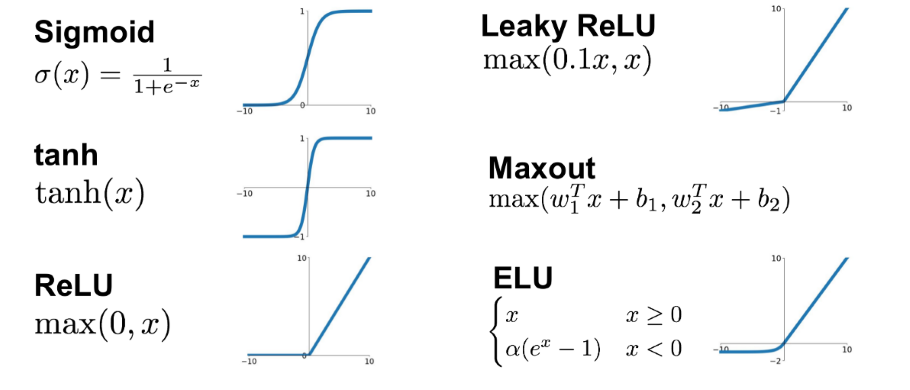
این شِما وقتی که واحدها برای ساخت لایهها به یکدیگر متصل میشوند، قدرت میگیرد. تابع فعالسازی چیزی است که به شبکه این امکان را میدهد که خصوصیات غیر خطی را فرض کند. برخی از متداولترین توابع فعالسازی مورد استفاده در شبکههای عصبی تابع «سیگموئید» (sigmoid)، «یکسوساز» (ReLu) و «تانژانت هیپربولیک» (Hyperbolic Tangent) هستند.
با یک راهکار ساده، خروجی واحد، مانند آنچه که در تصویر وجود دارد را میتوان به وسیله ŷ=σ(W⋅x+b) محاسبه کرد. این همان چیزی است که پاس دادن «پیشخور» (FeedForward) نامیده میشود. این خروجی، پیشبینی است که میتوان آن را با هدف حقیقی y از طریق تابع خطا (زیان) (Loss Function) مقایسه کرد. فرایند اجرای عقبگرد عملیات پیشخور که به منظور گسترش خطای محاسبه شده به هر یک از وزنها استفاده میشود را «پسانتشار» (Back-Propagation) میگویند.
یادگیری انتقال
یادگیری انتقال توانایی استفاده از مدل توسعه پیدا کرده برای یک وظیفه خاص، به عنوان نقطه شروع مدل در وظیفه دیگری است. میتوان از خروجی شبکه عصبی از پیش آموزش دیده به عنوان ویژگی شبکه عصبی کنونی استفاده کرد و تنها چیزی که در این راستا نیاز است، آموزش دادن لایههای شبکه است. «پایتورچ» (PyTorch) یک کتابخانه یادگیری ماشین متنباز بر پایه «کتابخانه تورچ» است و به طور گستردهای برای «بینایی کامپیوتری» (Computer Vision) و «پردازش زبان طبیعی» (NLP | Natural Language Processing) مورد استفاده قرار میگیرد.

پایتورچ با بسته torchvision عرضه میشود که شامل مجموعه دادههای محبوب، معماری مدل و تبدیلهای تصویر متداول برای بینایی کامپیوتری است. علاوه بر آن، چنانکه در مستندات این کتابخانه بیان شده است، زیربستههای مدل حاوی تعاریفی از مدل برای آدرسدهی وظایف گوناگون شامل دستهبندی تصاویر، «بخشبندی معنایی مبتنی بر پیکسل» (Pixelwise Semantic Segmentation)، «تشخیص شی» (Object Detection)، «بخشبندی نمونه» (Instance Segmentation)، «تشخیص نقطه کلیدی فرد» (Person Keypoint Detection) هستند. در این پروژه، از شبکههای vgg13 ،vgg11 و vgg16 استفاده شده است. همه این شبکهها شامل «شبکههای عصبی بسیار عمیق برای تشخیص تصویر بزرگ مقیاس» ( Very Deep Convolutional Networks for Large-Scale Image Recognition) هستند.
پروژه نمونه
پروژه نمونه مورد بررسی در اینجا، شامل آموزش دادن یک دستهبند تصاویر برای تشخیص گونههای گوناگون گلها است. علاوه بر آن، دستهبند به صورت برنامه کاربردی تبدیل خواهد شد، بدین معنا که افراد میتوانند کد را در ترمینال اجرا کنند تا با استفاده از مدل آموزش دیده، برای یک تصویر، پیشبینی انجام دهند. در ادامه، مثالهایی از گلهایی که قصد پیشبینی کردن دسته آنها وجود دارد، آورده شدهاند.

مثالی از گلها برای پیشبینی شدن
مجموعه داده به سه بخش «آموزش» (Training)، «ارزیابی» (Validation) و «آزمون» (Testing) تقسیم میشود. تعدادی تبدیل، مانند «مقیاسدهی» (Scaling)، «بریدن» (cropping) و flipping در این تصاویر اعمال شده است. این کار کمک میکند تا شبکه تعمیم پیدا کند و همین امر منجر به کارایی بهتر میشود. علاوه بر آن، تصاویر به ابعاد ۲۲۴×۲۲۴ پیکسل تغییر سایز داده شدهاند؛ زیرا این ابعاد برای شبکههای از پیش آموزش دیده شده لازم است. میتوان مثالی از این تبدیل را در زیر مشاهده کرد.
train_transforms = transforms.Compose([transforms.RandomRotation(30),
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[۰٫۲۲۹, ۰٫۲۲۴, ۰٫۲۲۵])])
اگر یک شبکه از پیش آموزش دیده vgg16 بارگذاری شود، میتوان چیزی مانند زیر را مشاهده کرد.
VGG( (features): Sequential( (۰): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (۱): ReLU(inplace) (۲): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (۳): ReLU(inplace) (۴): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (۵): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (۶): ReLU(inplace) (۷): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (۸): ReLU(inplace) (۹): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (۱۰): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (۱۱): ReLU(inplace) (۱۲): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (۱۳): ReLU(inplace) (۱۴): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (۱۵): ReLU(inplace) (۱۶): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (۱۷): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (۱۸): ReLU(inplace) (۱۹): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (۲۰): ReLU(inplace) (۲۱): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (۲۲): ReLU(inplace) (۲۳): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (۲۴): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (۲۵): ReLU(inplace) (۲۶): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (۲۷): ReLU(inplace) (۲۸): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (۲۹): ReLU(inplace) (۳۰): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) ) (classifier): Sequential( (۰): Linear(in_features=25088, out_features=4096, bias=True) (۱): ReLU(inplace) (۲): Dropout(p=0.5) (۳): Linear(in_features=4096, out_features=4096, bias=True) (۴): ReLU(inplace) (۵): Dropout(p=0.5) (۶): Linear(in_features=4096, out_features=1000, bias=True) ) )
شایان توجه است که شبکه از پیش آموزش دیده شده به عنوان «ویژگیها» (Features) در نظر گرفته میشود. تنها کاری که نیاز است انجام شود، ساختن شبکه عصبی با جایگذاری بخش دستهبند مدل از پیش آموزش دیده است. بنابراین، در این شبکه عصبی، با بخش ویژگیهای فراهم شده به وسیله vgg16 و با تصویر گلهای موجود، میتوان بخش دستهبندی شبکه را برای ساخت مدل آموزش داد.
ساخت شبکه
شبکه عصبی که بخش «دستهبند» از شبکه از پیش آموزش داده را جایگزین خواهد کرد، به راحتی به وسیله یک کلاس ساده قابل انجام است. این مورد، در زیر نمایش داده شده است.
from torch import nn
import torch.nn.functional as F
#The class bellow was created based in the one provided by Udacity
class Network(nn.Module):
def __init__(self, input_size, output_size, hidden_layers, drop_p=0.5):
''' Builds a feedforward network with arbitrary hidden layers.
Arguments
---------
input_size: integer, size of the input layer
output_size: integer, size of the output layer
hidden_layers: list of integers, the sizes of the hidden layers
'''
super().__init__()
# Input to a hidden layer
self.hidden_layers = nn.ModuleList([nn.Linear(input_size, hidden_layers[0])])
# Add a variable number of more hidden layers
layer_sizes = zip(hidden_layers[:-1], hidden_layers[1:])
self.hidden_layers.extend([nn.Linear(h1, h2) for h1, h2 in layer_sizes])
self.output = nn.Linear(hidden_layers[-1], output_size)
self.dropout = nn.Dropout(p=drop_p)
def forward(self, x):
''' Forward pass through the network, returns the output logits '''
for each in self.hidden_layers:
x = F.relu(each(x))
x = self.dropout(x)
x = self.output(x)
return F.log_softmax(x, dim=1)
شایان ذکر است که در این کلاس، از چیزی با عنوان DropOut استفاده شده است. مفهوم dropout بسیار ساده است: در هر تکرار از شبکه عصبی، به طور تصادفی درصدی از گرهها حذف میشوند که به ما در کاهش بیشبرازش کمک میکنند.
آموزش دادن شبکه
آموزش دادن شبکه، شامل مراحل زیر میشود:
- اجرای پاس پیشخور در شبکه عصبی و محاسبه پیشبینی برای y.
- پیشبینی و برچسبهای واقعی باید در تابع زیان درج شده باشند (در اینجا، برای این کار از NLLLoss یا Negative Log Likelihood Loss استفاده شده است).
- بر اساس تابع زیان، یک پاس پسانتشار برای گسترش خطا به دیگر گرهها انجام میشود.
- وزنها مجددا از طریق یک بهینهساز محاسبه میشوند (در اینجا، از بهینهسازی «آدام» (Adam) استفاده شده است).
- محاسبه نتایج اعتبارسنجی متقابل (زیان و صحت) برای نظارت کردن بر نتایج.
- تکرار کل فرایند برای N دوره.
در ادامه، مثالی از ۴ دوره اجرا آورده شده است.
Epoch 1/4.. Train loss: 4.150.. Validation loss: 2.798.. Validation accuracy: 0.365 Epoch 1/4.. Train loss: 2.595.. Validation loss: 1.550.. Validation accuracy: 0.608 Epoch 1/4.. Train loss: 1.916.. Validation loss: 1.143.. Validation accuracy: 0.681 Epoch 1/4.. Train loss: 1.724.. Validation loss: 0.970.. Validation accuracy: 0.733 Epoch 2/4.. Train loss: 1.496.. Validation loss: 0.805.. Validation accuracy: 0.782 Epoch 2/4.. Train loss: 1.277.. Validation loss: 0.829.. Validation accuracy: 0.769 Epoch 2/4.. Train loss: 1.261.. Validation loss: 0.705.. Validation accuracy: 0.811 Epoch 2/4.. Train loss: 1.156.. Validation loss: 0.644.. Validation accuracy: 0.808 Epoch 3/4.. Train loss: 1.111.. Validation loss: 0.608.. Validation accuracy: 0.828 Epoch 3/4.. Train loss: 1.043.. Validation loss: 0.527.. Validation accuracy: 0.865 Epoch 3/4.. Train loss: 1.007.. Validation loss: 0.616.. Validation accuracy: 0.820 Epoch 3/4.. Train loss: 0.998.. Validation loss: 0.528.. Validation accuracy: 0.861 Epoch 4/4.. Train loss: 0.993.. Validation loss: 0.533.. Validation accuracy: 0.849 Epoch 4/4.. Train loss: 0.896.. Validation loss: 0.476.. Validation accuracy: 0.863 Epoch 4/4.. Train loss: 0.915.. Validation loss: 0.446.. Validation accuracy: 0.876 Epoch 4/4.. Train loss: 0.818.. Validation loss: 0.505.. Validation accuracy: 0.874
میتوان مشاهده کرد که تابع زیان در حالی کاهش پیدا میکند که صحت برای دادههای اعتبارسنجی به شدت افزایش پیدا میکند.
ذخیرهسازی مدل
پس از آنکه مدل آموزش دید، نیاز به ذخیره کردن آن برای انجام پیشبینی است. در این وهله، گامهای زیر باید برداشته شوند:
- ذخیره کردن نگاشت کلاسها به اندیسها، شامل اسامی دستهها. بنابراین، میتوان نام گلهای پیشبینی شده را پیگیری کرد.
- یک چکپوینت مدل با اطلاعاتی پیرامون مدل، شامل اندازه ورودی شبکه ساخته میشود؛ سایز خروجی مدل (در اینجا برابر با ۱۰۲ است که تعداد گلهای مختلف است)؛ لایههای پهنان؛ درصد dropout و به همین ترتیب.
#Extract the class_to_idx transformation
model.class_to_idx = train_data.class_to_idx
#Put the model in CPU mode to allow predictions without having CUDA
model.to('cpu')
#Create the checkpoint
checkpoint = {'input_size':25088,
'output_size':102,
'hidden_layers':[each.out_features for each in classifier.hidden_layers],
'drop_p':0.2,
'state_dict':model.state_dict(),
'class_to_idx': model.class_to_idx}
filepath = 'checkpoint.pth'
#Save the model
torch.save(checkpoint, filepath)
انجام پیشبینی
برای انجام پیشبینی، همچنان نیاز به مقادیر کد زدن است. ابتدا نیاز به تبدیل هر تصویر ورودی به شیوهای است که با دادههای آموزش انجام میشود. این کار را میتوان با تابعی مخصوص این کار انجام داد.
#The function bellow process images in the very same way that was done with the testing and validation data
def process_image(image):
''' Scales, crops, and normalizes a PIL image for a PyTorch model,
returns an Numpy array
'''
# TODO: Process a PIL image for use in a PyTorch model
#Loading image with PIL (https://pillow.readthedocs.io/en/latest/reference/Image.html)
im = Image.open(image)
#Notice: te very same transformation applied to the test/validation data will be applied here
process = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[۰٫۲۲۹, ۰٫۲۲۴, ۰٫۲۲۵])])
return process(im)
در نهایت، فرایند بسیار ساده است: هنگامی که تصویر ورودی پردازش شد، میتوان مدل آموزش دیده را بارگذاری کرد و یک گام به جلو رفت. سپس، کلاسی با بیشترین احتمال وقوع از میان ۱۰۲ کلاس موجود دریافت و اندیس آن به گل متناظر نگاشت میشود. مثالی از پیشبینی انجام شده، در ادامه نمایش داده شده است.

در این مثال، محتملترین کلاس، «گل سپاسی بیساقه» (Stemless Gentian) است.
ساخت یک برنامه کاربردی
مفهوم بیان شده در بالا، در کلاسها و توابعی ماژولاریزه شده است که امکان انجام پیشبینی را با فراخوانی مدل از طریق ترمینال فراهم میکند. مثالهایی پیرامون چگونگی استفاده از این برنامه کاربردی در ترمینال، در ادامه آورده شده است.
آموزش دادن مدل
به منظور آموزش دادن مدل، فرد باید مسیر ورودی برای تصویر و آرگومانهای اختیاری مانند مدل از پیش آموزش دیده برای استفاده را (vgg13 ،vgg11 یا vgg16) بدهد؛ همچنین، باید مشخص کند که قصد استفاده از GPU را دارد یا نه و همچنین، نرخ یادگیری مورد انتظار و و اندازه لایههای پهان را مشخص کند.
python train.py ‘./flowers’
python train.py ‘./flowers’ — save_dir ‘./’
python train.py ‘./flowers’ — arch ‘vgg11’
python train.py ‘./flowers’ -l 0.005 -e 2 -a ‘vgg13’
python train.py ‘./flowers’ -l 0.005 -e 2 -a ‘vgg16’ — gpu
python train.py ‘./flowers’ — learning_rate 0.01 — hidden_units 2048 1024 — epochs 20 — gpu
پیشبینی گلها
به منظور انجام پیشبینی، فرد باید مسیر ورودی برای تصاویر را به منظور انجام پیشبینی و مسیر به مدل آموزش داده شده را ارائه کند. علاوه بر آن، یک فایل json با نام متناظر گلها برای هر کلاس (دسته) به عنوان یک آرگومان قابل ارسال است.
python predict.py ‘./flowers/test/15/image_06351.jpg’ ‘checkpoint.pth’
python predict.py ‘./flowers/test/15/image_06351.jpg’ ‘checkpoint.pth’ — category_names cat_to_name.json
python predict.py ‘./flowers/test/15/image_06351.jpg’ ‘checkpoint.pth’ — category_names cat_to_name.json — top_k 3
python predict.py ‘./flowers/test/15/image_06351.jpg’ ‘checkpoint.pth’ — category_names cat_to_name.json — top_k 5 — gpu
جمعبندی
در این مطلب، ابتدا مفهوم «یادگیری انتقال» و ارتباط آن به یادگیری عمیق شرح داده شد. سپس، بیان شد که میتوان از یک شبکه از پیش آموزش داده شده که برای هدف خاصی ساخته شده است، به عنوان ویژگی برای آموزش دادن شبکه عصبی متفاوتی با هدف متفاوت استفاده کرد. سپس، از اعمال این مفاهیم برای پیشبینی کلاسهای مختلف گلهای پیدا شده در انگلستان استفاده شد. توابع و کلاسهای مشاهده شده به منظور ساخت یک برنامه کاربردی کامل که قادر به آموزش یک شبکه عصبی است و انجام پیشبینی برای تصویر ورودی داده شده، ماژولاریزه شدند.
اگر مطلب بالا برای شما مفید بوده، آموزشهای زیر نیز به شما پیشنهاد میشود:
- مجموعه آموزشهای دادهکاوی و یادگیری ماشین
- آموزش دادهکاوی یا Data Mining در متلب
- مجموعه آموزشهای برنامهنویسی پایتون
- زبان برنامهنویسی پایتون (Python) — از صفر تا صد
- یادگیری علم داده (Data Science) با پایتون — از صفر تا صد
- چگونه یک دانشمند داده شوید؟ — راهنمای گامبهگام به همراه معرفی منابع
مجموعه: برنامه نویسی, داده کاوی, شبکه های عصبی, مهندسی کامپیوتر, هوش مصنوعی
