دسته بندی چند کلاسی با سایکیت لرن — راهنمای کاربردی
«دستهبندی چند کلاسی» (Multiclass Classification) یک مسئله متداول در «یادگیری نظارت شده» (Supervised Learning) است. در این مطلب، روش انجام دسته بندی چند کلاسی با سایکیت لرن مورد بررسی قرار گرفته است.
دسته بندی چند کلاسی با سایکیت لرن
در ادامه، روش انجام دسته بندی چند کلاسی با سایکیت لرن با ارائه یک مثال و حل آن، آموزش داده شده است. در این راستا، ابتدا نیاز به بیان مسئله است.
مسئله: مجموعه دادهای از m نمونه آموزش، داده شده است. هر یک از این نمونه دادهها شامل اطلاعاتی به شکل ویژگیهای گوناگون و یک برچسب هستند. هر برچسب، مربوط به کلاسی است که دادههای آموزش متعلق به آن هستند. در دستهبندی چند کلاسی، مجموعه متناهی از کلاسها وجود دارد. هر نمونه آموزش دارای n ویژگی است.
برای مثال، به منظور شناسایی انواع مختلفی از میوهها، ویژگیهای شکل (Shape)، رنگ (Color) و «شعاع» (Radius) میتوانند ویژگیها و «سیب» (Apple)، پرتقال (Orange) و «موز» (Banana) میتوانند برچسبهای کلاسهای مختلف باشند. در دستهبندی چندکلاسی، یک دستهبند با استفاده از دادههای آموزش (Train Data) آموزش داده میشود و از این دستهبند برای دستهبندی نمونههای جدید استفاده میشود.
در ادامه این مطلب، از روشهای دستهبندی چندکلاسی مانند «k نزدیکترین همسایگی» (K-Nearest Neighbors Algorithm)، «درخت تصمیم» (Decision Trees)، «ماشین بردار پشتیبان» (Support Vector Machine | SVM) و دیگر موارد استفاده میشود. سپس، صحت این موارد روی دادههای تست بررسی میشود. همه این کارها با استفاده از کتابخانه پایتون «سایکیتلرن» (Scikit-Learn) انجام میشود. در این راستا، اقدامات زیر باید صورت پذیرد.
- بارگذاری مجموعه داده از منبع
- تقسیم کردن مجموعه داده به دو بخش دادههای «آموزش» (Train) و دادههای آزمون (Test)
- آموزش دادن دستهبندهای درخت تصمیم، ماشین بردار پشتیبان و K نزدیکترین همسایگی روی دادههای آموزش
- استفاده از دستهبندهای بالا برای پیشبینی برچسب برای دادههای تست
- اندازهگیری صحت و بصریسازی دستهبندها
دستهبند درخت تصمیم
دستهبندی درخت تصمیم یک رویکرد سیستماتیک بری دستهبندی چند دستهای (چند کلاسی) است. این دستهبند، یک مجموع از پرسشهای مربوط به ویژگیها را دریافت میکند. الگوریتم دستهبندی درخت تصمیم را میتوان روی درخت دودویی بصریسازی کرد. روی ریشه و هر یک از گرههای داخلی، یک پرسش قرار میگیرد و دادهها روی گرهها به رکوردهای جدایی تقسیم میشوند که مشخصههای متفاوتی دارند. برگهای درخت به کلاسهایی ارجاع دارند که در آنها مجموعه داده به دو رکورد مجزا تقسیم میشود که دارای مشخصههای متفاوتی هستند. برگهای درخت به کلاسهایی ارجاع دارند که در آنها دادهها دارای مشخصههای متفاوتی هستند. برگهای درخت به کلاسی ارجاع دارند که در آن، مجموعه داده تقسیم میشود. در قطعه کد زیر، روش نوشتن دستهبند درخت تصمیم با بهرهگیری از کتابخانه «سایکیتلرن» (Scikit-Learn) آموزش داده میشود.
# importing necessary libraries
from sklearn import datasets
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
# loading the iris dataset
iris = datasets.load_iris()
# X -> features, y -> label
X = iris.data
y = iris.target
# dividing X, y into train and test data
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 0)
# training a DescisionTreeClassifier
from sklearn.tree import DecisionTreeClassifier
dtree_model = DecisionTreeClassifier(max_depth = 2).fit(X_train, y_train)
dtree_predictions = dtree_model.predict(X_test)
# creating a confusion matrix
cm = confusion_matrix(y_test, dtree_predictions)دستهبند ماشین بردار پشتیبان
«ماشین بردار پشتیبان» (Support Vector Machine) یک روش دستهبندی است که به طور خاص هنگامی که بردار ویژگی دارای ابعاد بالا باشد موثر و کارا است. در کتابخانه سایکیتلرن میتوان تابع کرنل (در اینجا، تابع خطی) را تعیین کرد.
# importing necessary libraries
from sklearn import datasets
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
# loading the iris dataset
iris = datasets.load_iris()
# X -> features, y -> label
X = iris.data
y = iris.target
# dividing X, y into train and test data
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 0)
# training a linear SVM classifier
from sklearn.svm import SVC
svm_model_linear = SVC(kernel = 'linear', C = 1).fit(X_train, y_train)
svm_predictions = svm_model_linear.predict(X_test)
# model accuracy for X_test
accuracy = svm_model_linear.score(X_test, y_test)
# creating a confusion matrix
cm = confusion_matrix(y_test, svm_predictions)K نزدیکترین همسایگی
K نزدیکترین همسایگی سادهترین الگریتم دستهبندی است. این الگوریتم دسته بندی به ساختار دادهها مربوط نیست. هنگامی که یک نمونه جدید وجود داشته باشد، K نزدیکترین همسایگی آن از روی دادههای آموزش بررسی میشود. فاصله بین دو نمونه میتواند فاصله اقلیدسی بین بردارهای ویژگی آنها باشد. کلاس اکثریت در میان K نزدیکترین همسایگی به عنوان کلاس نمونه جدید در نظر گرفته میشود.
# importing necessary libraries
from sklearn import datasets
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
# loading the iris dataset
iris = datasets.load_iris()
# X -> features, y -> label
X = iris.data
y = iris.target
# dividing X, y into train and test data
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 0)
# training a KNN classifier
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors = 7).fit(X_train, y_train)
# accuracy on X_test
accuracy = knn.score(X_test, y_test)
print accuracy
# creating a confusion matrix
knn_predictions = knn.predict(X_test)
cm = confusion_matrix(y_test, knn_predictions)دستهبند بیز ساده
روش دستهبندی بیز ساده بر مبنای نظریه بیز است. به این نوع دستهبندی به این دلیل «ساده» (Naive) گفته میشود که فرض میکند بین هر جفت از ویژگیهای موجود در دادهها استقلال وجود دارد. فرض میشود که (x1, x2, …, xn) بردار ویژگی و Y برچسب کلاس متناظر با این بردار ویژگی جدید است. با اعمال نظریه بیز؛ داریم:
![]()
با توجه به اینکه x1, x2, …, xn مستقل از یکدیگر هستند، داریم:
![]()
با توجه به ثابت بودن (P(x1, …, xn، این بخش حذف و تناسب قرار داده میشود:
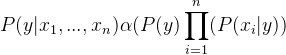
بنابراین، برچسب کلاس به وسیله رابطه زیر محاسبه میشود:
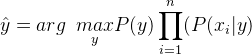
فراوانی نسبی برچسب کلاس y در مجموعه داده آموزش است. در دستهبندی بیز ساده گاوسی، (P(xi | y به صورت زیر محاسبه میشود:
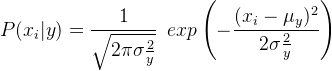
# importing necessary libraries
from sklearn import datasets
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
# loading the iris dataset
iris = datasets.load_iris()
# X -> features, y -> label
X = iris.data
y = iris.target
# dividing X, y into train and test data
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 0)
# training a Naive Bayes classifier
from sklearn.naive_bayes import GaussianNB
gnb = GaussianNB().fit(X_train, y_train)
gnb_predictions = gnb.predict(X_test)
# accuracy on X_test
accuracy = gnb.score(X_test, y_test)
print accuracy
# creating a confusion matrix
cm = confusion_matrix(y_test, gnb_predictions)منبع [+]
مجموعه: برنامه نویسی, داده کاوی
